how I think about llms
published:

One thing you learn when working with complex systems is that the only tools that truly help you understand them are the simple ones. Flexible approaches survive as the problem grows, while rigid and hard-coded solutions fall apart as soon as the dimensionality explodes. Only the simple lenses work, whether you are looking at 3 dimensions or 3 million. Large Language Models (LLMs) are a perfect example. They are incredibly complex systems, the product of years of research and the combined efforts of teams in billion-dollar companies around the world. It’s almost overwhelming when you stop and deeply think about it. Yet, from the right angle, these models can become approachable.
Here, I want to describe how I think about these models and how I try to extract useful bits of information from them. I rely on a small set of simple heuristics that help me reason about both small and large models, encoder–decoder architectures, autoregressive models, with or without RoPE, and the like. Probably some of these heristics are either wrong or useless, but my hope is that they still make LLMs a bit more intuitive for you as well.
llms are fat, lossy compressions of their training data.
A pretrained language model is essentially a giant, lossy compression of its text dataset. Its weights store a probabilistic approximation of the joint token distribution. The model behaves more like a “fuzzy, probabilistic ZIP file” (thanks Karpathy). Correlation between tokens are stored in the weights, and the only way to access those correlations is by running inference with new inputs. Self-attention uses your input tokens as anchors to navigate this compressed space, making LLMs behave like interpolative databases.during pretraining, the dominant axis of scaling is data.
Once the architecture is fixed, pretraining is essentially about feeding the model more data. Parameters and compute matter only insofar as they enable the model to make better use of that data. There is not a separate compute-only scaling axis (if we had one, pretraining would likely look different). Scaling improves the model’s ability to reduce the reducible part of cross-entropy by capturing more regularities in the data, while performance ultimately plateaus at the irreducible entropy (given a sentence, there might be many valid words that follow that given sentence).performance makes sense only when considering the dataset.
Perplexity is not an absolute measure of intelligence, but a property of the model–dataset pair. A dataset with low entropy yields low perplexity even for simple models, and vice versa. Model performance is therefore inseparable from dataset quality and structure. The distribution you train on determines the behaviours the model can express or amplify at inference.
If these basic observations feel intuitive, then the following should also make sense (at least it does to me):
- scaling laws are not that surprising?
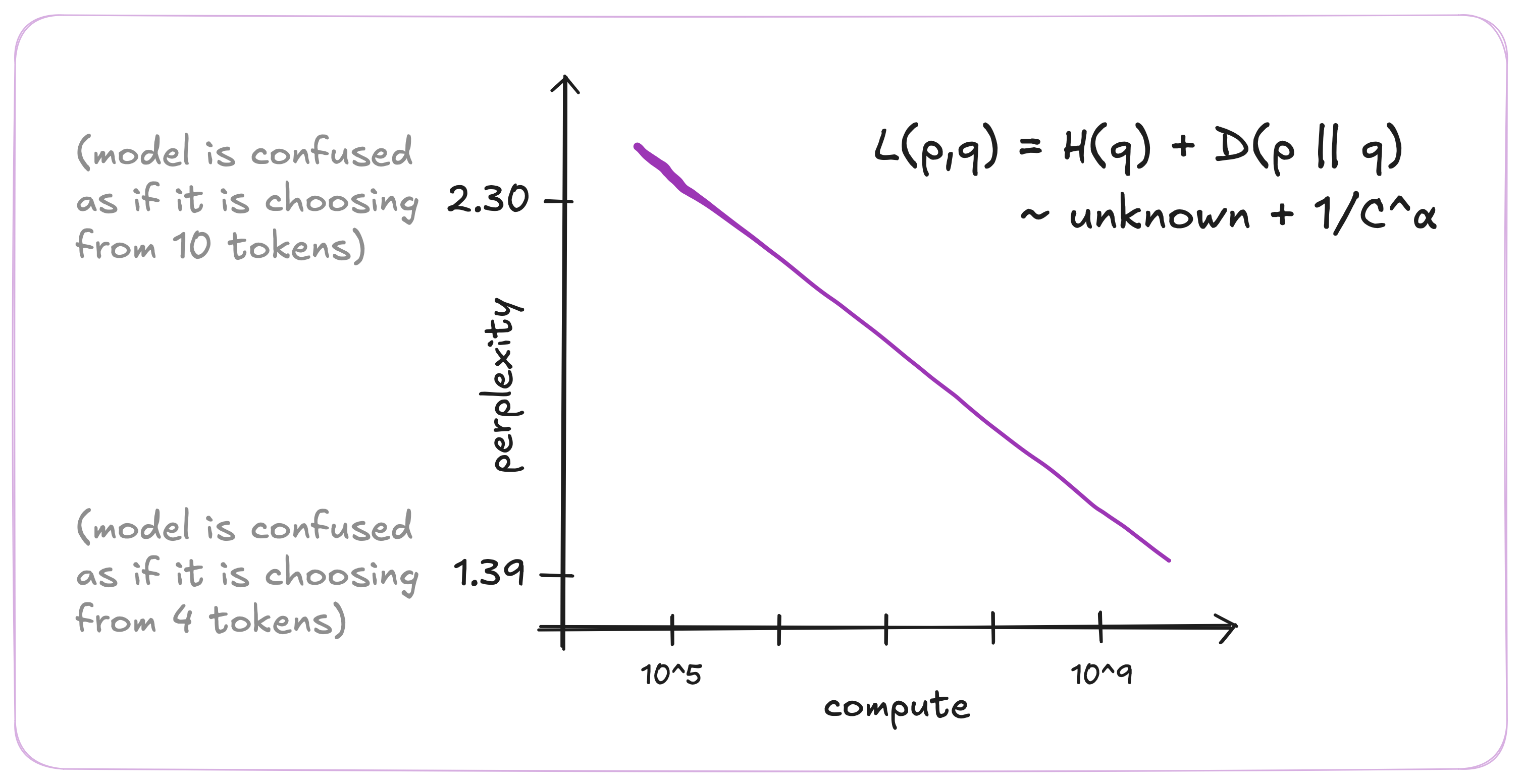
Large corpus of text have zipf-like distribution of tokens where the frequency of tokens follows a power-law. Predicting the next token over a massive text corpus is difficult, and it requires a complex model that can learn the statistical relationships between tokens. As model capacity increases, it allocates its computational budget to increasingly rare patterns. This creates smooth, predictable, diminishing-returns behavior, where x10 more compute yields roughly linear improvements in log-perplexity. The model is effectively “unlocking” a few more rare events at a time. This allows to make better predictions across many sentences, decreasing a bit the surprisal of multiple tokens. Since models can potentially store 16bits per parameter (assuming float16) and have up to billions of parameters, more compute can unlock new compression at scale since there is a lot of space. Furthermore, because the dataset has an intrinsic entropy, improvements must eventually plateau at an irreducible error.
emergent abilities are not that surprising?
Individual benchmarks can show seemingly abrupt ‘emergent’ jumps, but if you evaluate with continuous metrics or look at aggregate behavior over many tasks, the curves are typically smooth again. In other words, what looks like a sharp phase transition on a single benchmark is often just one threshold on top of an underlying, smooth improvement in modeling the data distribution. Indeed, many benchmarks live as subdomains of the much larger pretraining distribution. As the model’s fit to that global distribution improves, competence on these narrower subdomains often appears as a side effect, rather than something fundamentally new..in-context learning is not that surprising?
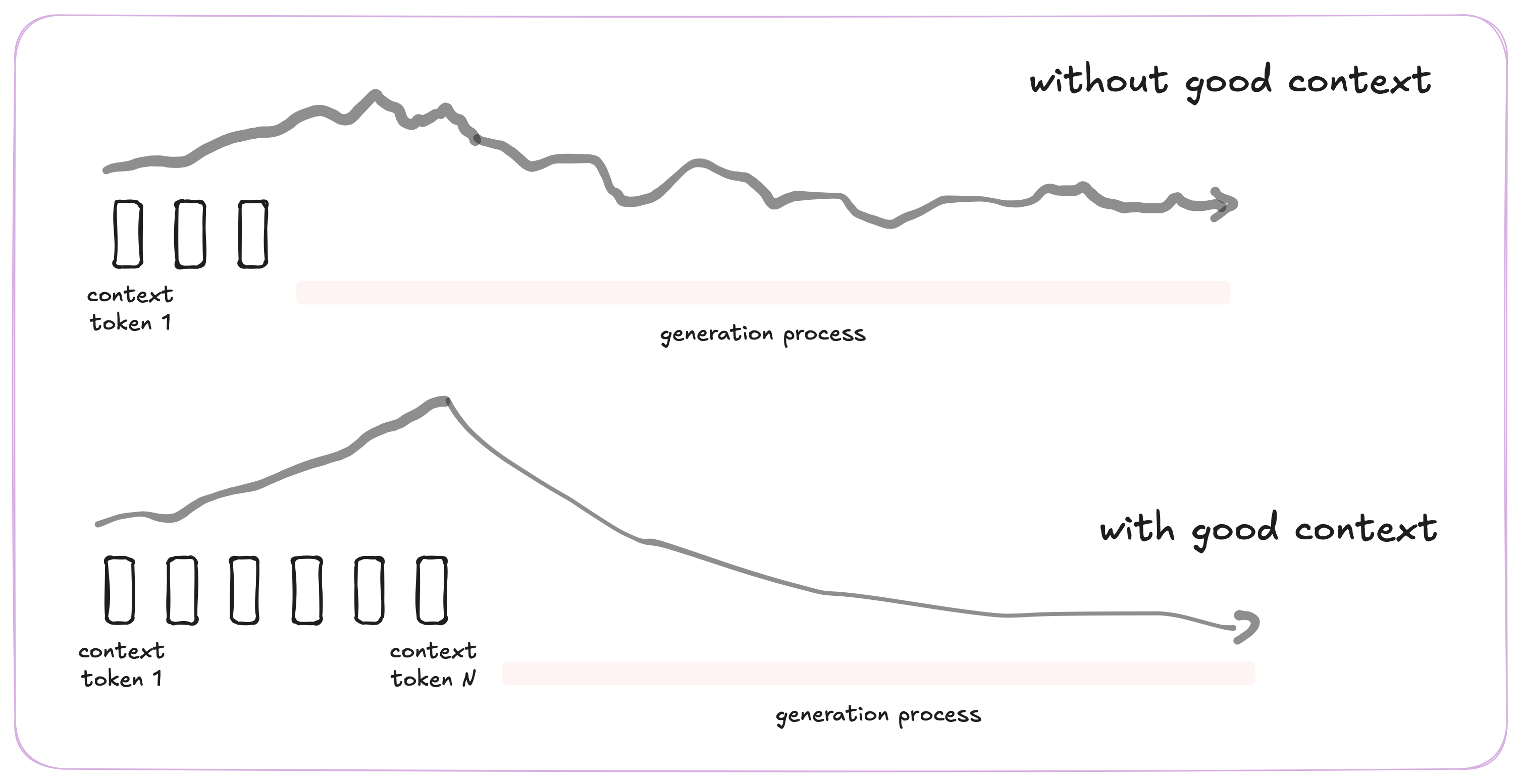
Without context, the model must rely entirely on its hazy, compressed memory. But when you provide examples directly in the input, self-attention can use the KV cache to refer to fresh, precise information at test time. This is often far cleaner than recalling something buried deep in the weights. Thus, in-context learning is a natural consequence of giving the model a temporary, token-addressable memory that interacts with the same attention machinery as its weights. For that to happen, you need to be able to stuff the KV cache with enough information, and to be able to compress well the corpus. Thus, this is expected to be something that is observed at scale (that is, longer context window for longer KV cache, more layers for better compression).
- llms naturally behave as simulators, and this is not that surprising?
Training on large human text implicitly means learning the distribution over how humans produce text. That distribution contains latent structure about goals, reasoning, conversational dynamics, personas, planning, and world knowledge. As the model improves at compressing this data, it also improves at reproducing the generative processes that produced it. Therefore, you can do the two following things: (1) given a context, you can enforce specific outputs with supervised training (this is called supervised fine tuning or SFT), (2) given a context, you can make it explore output streams and rewards the ones leading to a desired answer (this is called reinforcement learning). The richer the model, the better it will approximate conditional trajectories in the very large space of human-generated text.

side notes:
- architectural choices still matter locally. The way you allocate compute across architecture dimensions can have strong local effects. For example, increasing the context window versus increasing depth (number of layers) will change which dependencies the model can represent and what kinds of tasks it excels at. These design decisions modulate performance on specific problems, even if the global scaling story is still mostly about data.
- with post-training, things get more complicated. Once you enter post-training (alignment, instruction tuning, RLHF, RL, etc..) the clean relationship between data, model capacity, and behavior becomes much messier. The gap between how models are trained and how they are used grows larger. As a result, behaviors that were predictable under next-token prediction can become less stable, more context-dependent, and more sensitive to prompting and decoding strategies.
- test-time training adds yet another layer of complexity. Training at inference time effectively blurries the boundary between pretraining, post-training, and generation. This creates new behaviors that are not necessarily explained by pretraining scaling laws alone.