what if we make research compute-bound?
Science does not look like an algorithm from the inside. It looks more like confusion. You read papers, you talk with people, you get inspired by famous, hyped Nature papers, you try something, it fails, you change the setup, you run another experiment, you stare at a plot, you realize the metric was wrong, you go back, you write things down, you realize later you should have logged notes better, you compress the mess into a cleaner explanation, and eventually, if you are lucky, you understand one small piece of the world better than before.
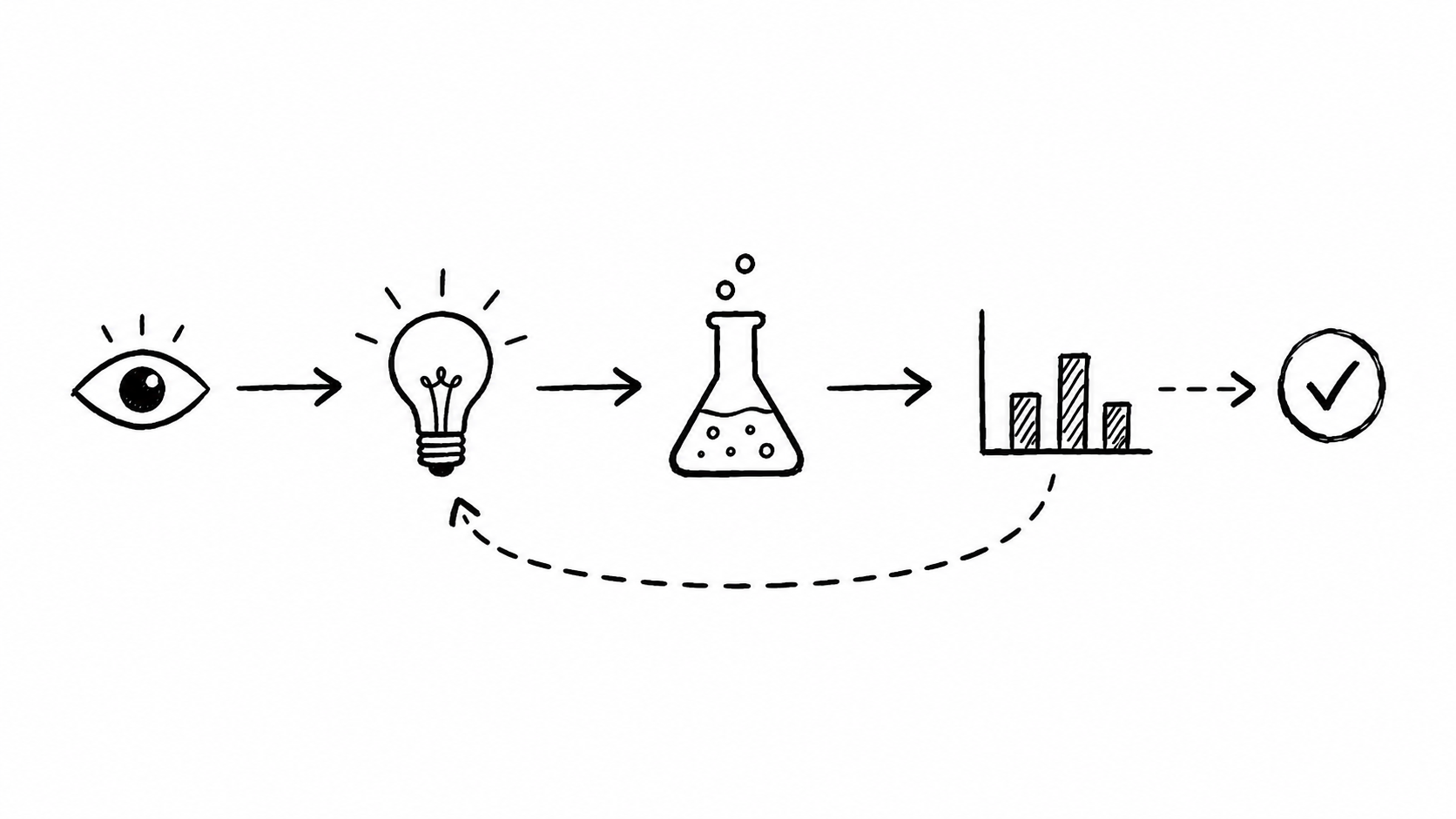
But the structure of the scientific method is “fairly” simple:
- take a current model of the world.
- find the places where that model is uncertain.
- propose possible explanations.
- test them against reality.
- update the model.
That is an algorithm.
For most of human history, this algorithm has been implemented on a massive biological and institutional substrate. The compute units were human brains. The memory system was papers, notebooks, codebases, conversations, lectures, books, and the half-compressed context living inside experts. The communication network was language, conferences, emails, universities, labs, peer review, and all the strange social machinery we built around knowledge.
Human brains are powerful, but they are hard to synchronize. Institutions preserve knowledge, but they are slow. Papers communicate results, but they are lossy renderings of the actual research process. Most failed experiments disappear. Most tacit knowledge never gets written down. Most context is local to a person, a lab, or a company. Although this substrate worked unbelievably well, it is arguably incredibly messy and often slow.
That being said, maybe science has not been slow only because discovery is hard. Maybe science has also been slow because the scientific method has been running on a bad machine.
1. the roofline of science.
In machine learning systems, one useful way to think about performance is arithmetic intensity. Roughly:
\[\text{arithmetic intensity} = \frac{\text{compute}}{\text{data movement}}\]If an operation does many computations for every byte it moves, it is compute-bound. Matrix multiplication is like this: you load data, reuse it many times, and do a lot of useful work. If an operation does very little computation for every byte it moves, it is memory-bound. The hardware spends most of its time moving information around instead of doing math.
I think the same lens is useful for science.
Of course, the scientific method does not literally run FLOPs. But it does have operations. A scientist generates hypotheses, compares explanations, designs experiments, runs code, measures outcomes, interprets results, notices contradictions, compresses evidence, and updates a model of the world.
And science also moves data. It moves papers, datasets, code, lab notes, figures, emails, assumptions, intuitions, failed attempts, experimental logs, and social context.
So we can define a rough analogy:
\[\text{scientific intensity} = \frac{\text{useful model-updating operations}} {\text{information moved through the research system}}\]The important word is useful.
A research system can generate thousands of experiments and still learn almost nothing. It can move enormous amounts of information through papers, meetings, and codebases while barely updating its model of the world. The goal is not pure operations, but compression: transform uncertainty into useful structure.
2. science is probably memory-bound.
It is easy to think that science is compute-bound. Add more researchers, more labs, more funding, more PhDs. Add more papers. Surely the system should go faster. This is, unfortunately, how many policymakers think as well.
I would say that a lot of science is probably memory-bound.
The bottleneck is not always the number of brains. The bottleneck is the bandwidth between brains, the quality of the shared memory, and the ability to preserve the real state of the search.
A paper is a tiny compressed artifact. It usually contains the successful path, not the full tree. It hides the dead ends, the bad baselines, the wrong metrics, the confusing bugs, the private conversations, the decisions that mattered, and the sequence of beliefs that changed along the way. This means that every reader has to decompress the paper back into a mental model. Every new lab has to reconstruct missing context. Every student has to rediscover tacit knowledge. Every failed experiment that is not recorded becomes information that the global system paid for but did not keep.
That is a memory and bandwidth problem. Arguably, the total amount of effective model-updating operations done by biological brains is very much bottlenecked by the available information.
Humans communicate through language, which is incredibly powerful but very low bandwidth compared to the internal state of a research project. The true state of a project is not just the final PDF. It is a flow of hypotheses, artifacts, experiments, failures, measurements, contradictions, and decisions.
But most of that flow never becomes a first-class object; it just stays in people’s heads, it gets distilled, and eventually lost.
3. moving to a better substrate.
If the scientific method is an algorithm, then we can ask a systems question: What is the right substrate for running it?
The old substrate was biological and institutional. The new substrate can be computational. Agents, code execution, persistent memory, experiment DAGs, tool calls, verifiers, search, simulations, and external compute.
This way, humans can move yet another level in the abstraction hierarchy. Instead of manually carrying all context, humans can define the taste, constraints, objectives, questions, and interpretations. The machine can run more of the search. It can branch more. It can preserve more state. It can test more. It can make the hidden graph explicit.
If this works, the bottleneck can move. The scientific method can become less memory-bound and more compute-bound.
And once something becomes compute-bound, scaling becomes much more direct. You can run more branches. You can allocate more inference. You can repeat experiments. You can test more baselines. You can search wider. You can let many agents explore different parts of the hypothesis space and merge the useful parts back into the graph.
Thus, we can outsource the scientific method to more compute. Not because compute magically creates understanding, but because the algorithm has been implemented in a way in which compute can be converted into useful model updates.
4. taste is the efficiency of the algorithm.
Making science executable does not mean making science good. A bad research loop can burn infinite compute and learn nothing. It can run experiments that do not discriminate between hypotheses. It can optimize the wrong metric. It can generate endless plausible ideas that never touch reality.
This is where research taste matters: research taste is the efficiency of the scientific algorithm.
It efficiently decides which uncertainty matters, which experiment is worth running, which baseline is fair, which result is noise, which failure is interesting, and which branch should be killed early. Two research systems can spend the same compute and produce completely different amounts of understanding.
Good taste increases this ratio of useful model updates per unit of information.
This is also why automating science is not only an infrastructure problem. It is a taste problem. The system needs memory, execution, and parallelism, but it also needs heuristics for choosing the next experiment with high expected information gain.
5. science has always been externalized intelligence.
Writing externalized memory. Mathematics externalized reasoning. Instruments externalized perception. Computers externalized calculation. AI agents may externalize part of the research loop itself.
And if that happens, the unit of science changes. It is no longer only the paper, but also the graph of the search. The living model of the world. The evolving structure that tells us what we believed, why we believed it, what we tested, what broke, and what we should try next.