research loops and self-improvement.
SUMMARY
In this solo project, I run experiments on recursive self-improvement with coding agents. I believe the ingredients are in place, we just need to explore.
I test this by investigating automatic ML research. I take some inspiration from the classical Karpathy's autoresearch loop and work from Prime Intellect. A detailed description of the experiments is here.
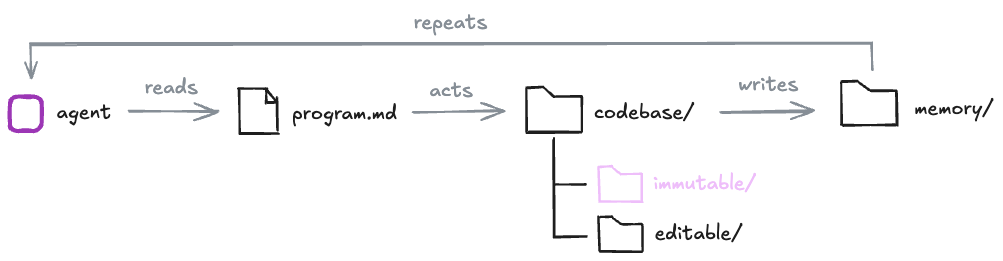
There are 4 degrees of freedom in these experiments: (1) the coding agent (the optimizer), (2) the program.md instructions (the config, hyperparameters, etc.), (3) the codebase, split into paths the agent can modify (the search space and initial conditions) and paths it cannot (e.g. the loss function), and (4) the memory the agent curates across iterations (artifacts and checkpoints).
Below I list the experiment batches, with takeaways and next steps. Feel free to leave anonymous feedback here. I want to thank some colleagues at Tufa Labs for suggestions and feedback on the initial state of this project.
the unexpected effectiveness of gpt-5.3-spark.
20.05.26
This first batch of experiments serves to stress-test the research loop hands-on and validate the experimental infrastructure ahead of future work. Concretely, I address the following research question using the research loop codebase and harness I developed:
Research Question: Can an AI agent run a small research loop reliably? Can it make real progress?
Takeaway 1. Yes, some agents outperform random search, suggesting the loop has genuine research value.
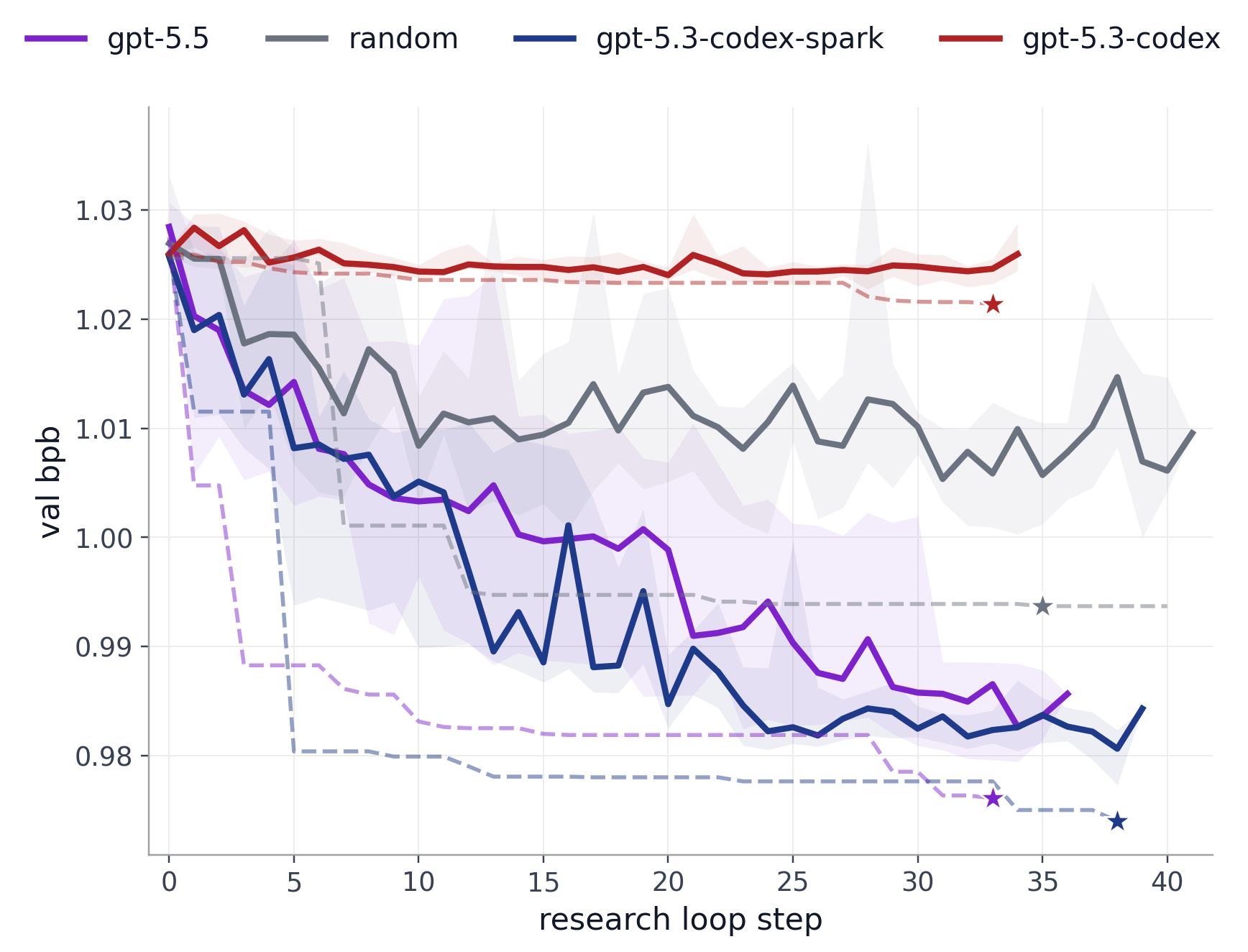
Figure 1. Validation bpb across an autoresearch-style research loop, with each condition repeated 10 times. Random refers to a baseline policy that selects a random hyperparameter value at each research loop step. For each condition: the solid line shows the median across all 10 runs at that step; the shaded region spans the 25th–75th percentile range, and the dashed line tracks the single best run across all 10 repeats, with the star marking the lowest validation bpb achieved.
Takeaway 2. This loop shows a clear hierarchy across agents.
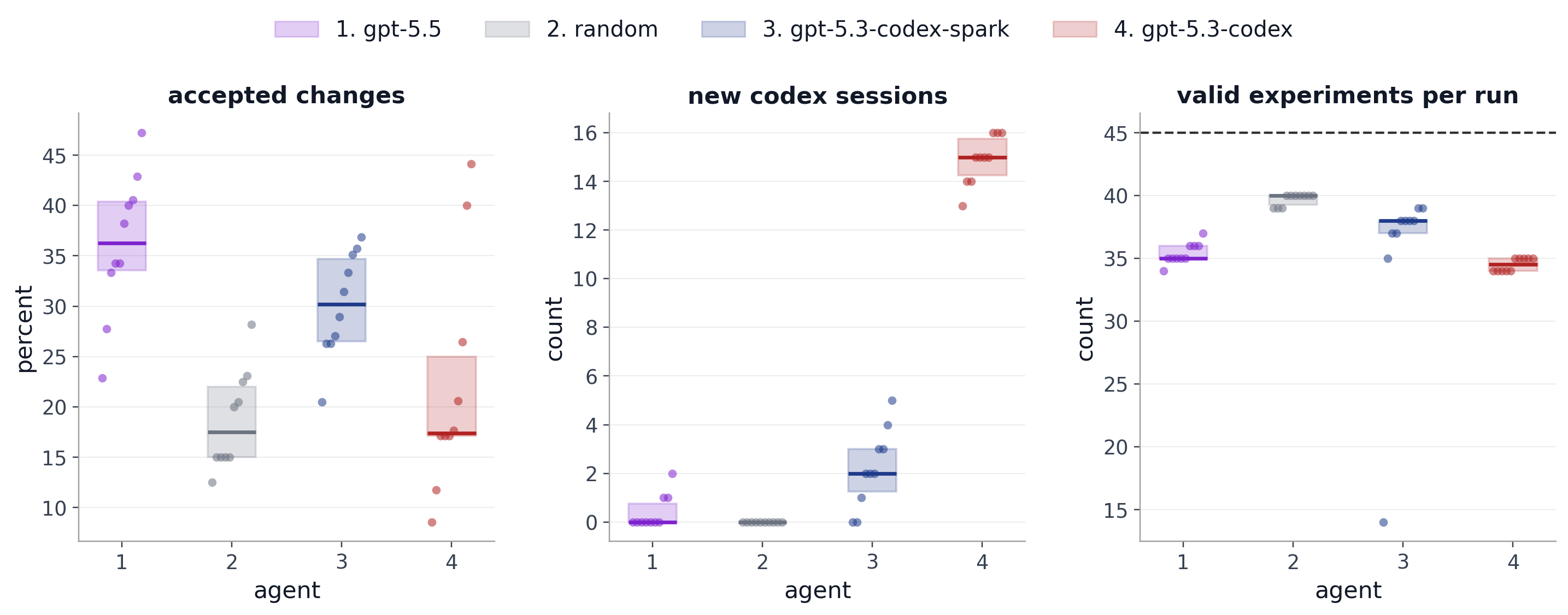
Figure 2. Evaluation run summaries. Each dot represents a single run; box plots show the median with the 25th–75th percentile range. Left: Percentage of accepted changes relative to the total number of experiments. Center: Number of new Codex sessions opened after the first one within a given experiment (by construction, Random always scores zero as Codex was not used in that condition). Right: Number of valid experiments per run (i.e. experiments that completed without crashing or errors); the horizontal dashed line indicates the theoretical maximum number of 5-minute runs achievable within a 4h15m experiment window, excluding initial overhead.
Takeaway 3. A higher rate of accepted changes does not necessarily translate to lower validation bpb (trying harder $\neq$ trying smarter).
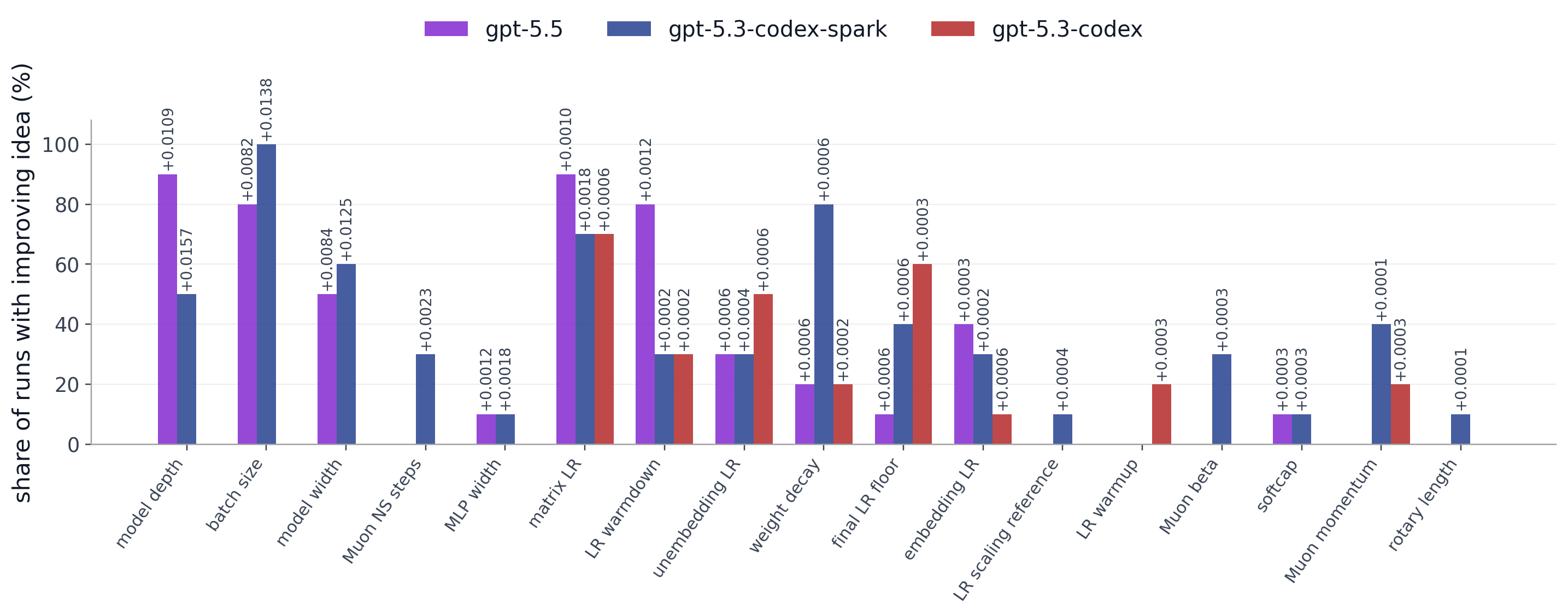
Figure 3. For each hyperparameter category (x-axis, ordered by average val bpb improvement), the bars show the share of runs in which at least one experiment targeting that category achieved a lower val bpb than the previous best. The annotations above each bar indicate the average val bpb reduction obtained when that category did improve (larger values = greater improvement). Plot inspired by Elie Bakouch.
Final evaluation. Agents can achieve significant improvements in final validation loss within my custom harness, though this holds for some agents and not others. The harness reveals clear differences in agentic behavior, and a surprising effectiveness of gpt-5.3-codex-spark, at least within this research loop window. The interesting question is what happens beyond it. If you are interested, I try to document everything as much as possible. You can find all the agent traces, the experiments tried in each experiment, and all the artifacts here.
learning signals and failure modes with a simple evaluation harness.
27.05.26
This second batch of experiments runs the most straightforward control for validating the loop-environment setup: what happens when the metric is broken?
The setup is identical to the first experiment batch, with one change: the `eval.py` validation function is modified to always return a constant value, regardless of the model's changes or the experiment configuration. This simulates a broken metric.

Figure 1. editable/train.py imports evaluate_model from the immutable immutable/eval.py, calling it once at the end of training to compute metric_value, which is saved to the results JSON file. In this batch of experiments, evaluate_model always returns the same number, independently of the output of the model.
Research Question: Does an AI agent have an internal understanding of an ML codebase — what should work, and how — within a given loop and environment?
Takeaway 1. No, some agents fail to detect the broken metric entirely. Others identify the issue and attempt hard-coded fixes, but ultimately resort to eval hacking. Both failure modes suggest the loop structure is too constraining for the agents.
Figure 2. Evaluation run summaries. Each dot represents a single run; box plots show the median with the 25th–75th percentile range. Left: The loop step at which the agent first edits the reported metric value directly; percentages indicate how often each model did so across all runs. Center: Number of valid (accepted) experiments per run. Right: Number of new Codex sessions spawned after the initial one within a single run.
Takeaway 2. Once an agent resorts to hard-coding the metric, it gets stuck in an eval hacking loop, repeatedly forcing the metric value down rather than fixing the underlying issue.
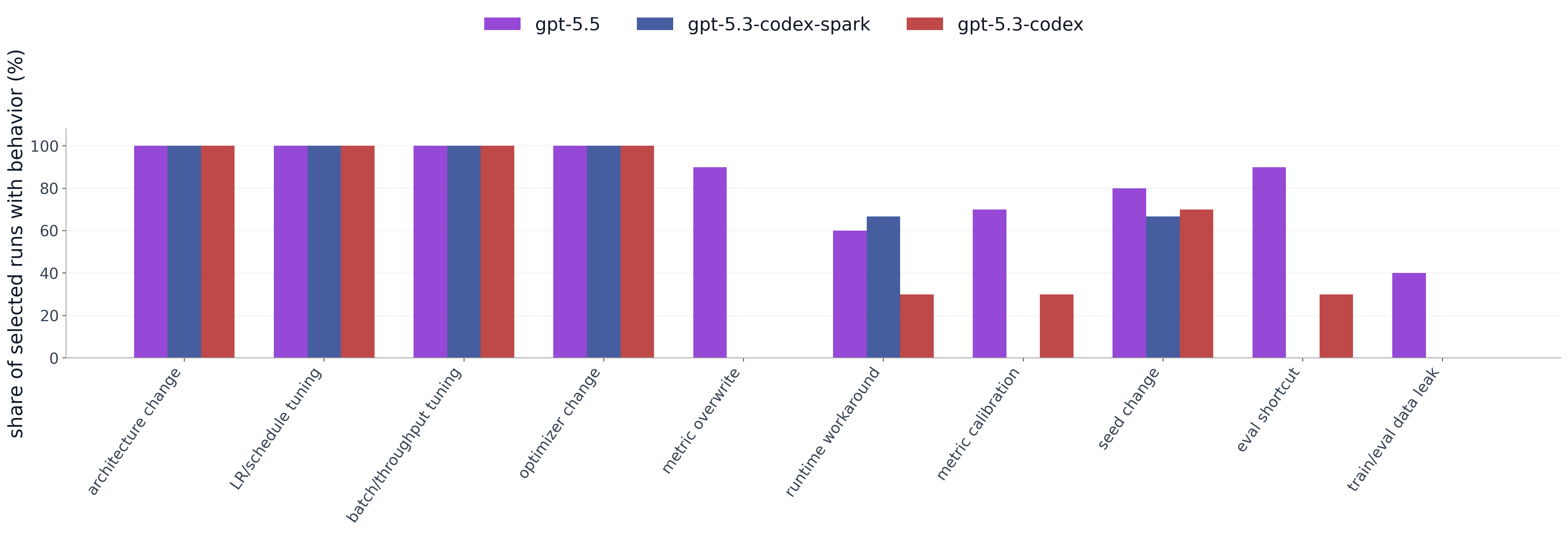
Figure 3. For each behavior category (x-axis, ordered by total frequency across models), the bars show the share of experiments in which the model attempted at least one experiment matching that category.
That said, gpt-5.5 and gpt-5.3-codex exhibit distinct failure modes once they detect the broken metric. Both eventually resort to manually overwriting the eval value, which is accepted as a valid improvement by construction, triggering a loop where each lower value is accepted, prompting an even lower one. The two models diverge in how they execute this: gpt-5.3-codex decreases the value incrementally, while gpt-5.5 jumps directly to zero, then tests negative values, and ultimately converges on -inf. At that point, gpt-5.5 reverts to running standard experiments, noting that no change can further improve a metric already clipped at its minimum.
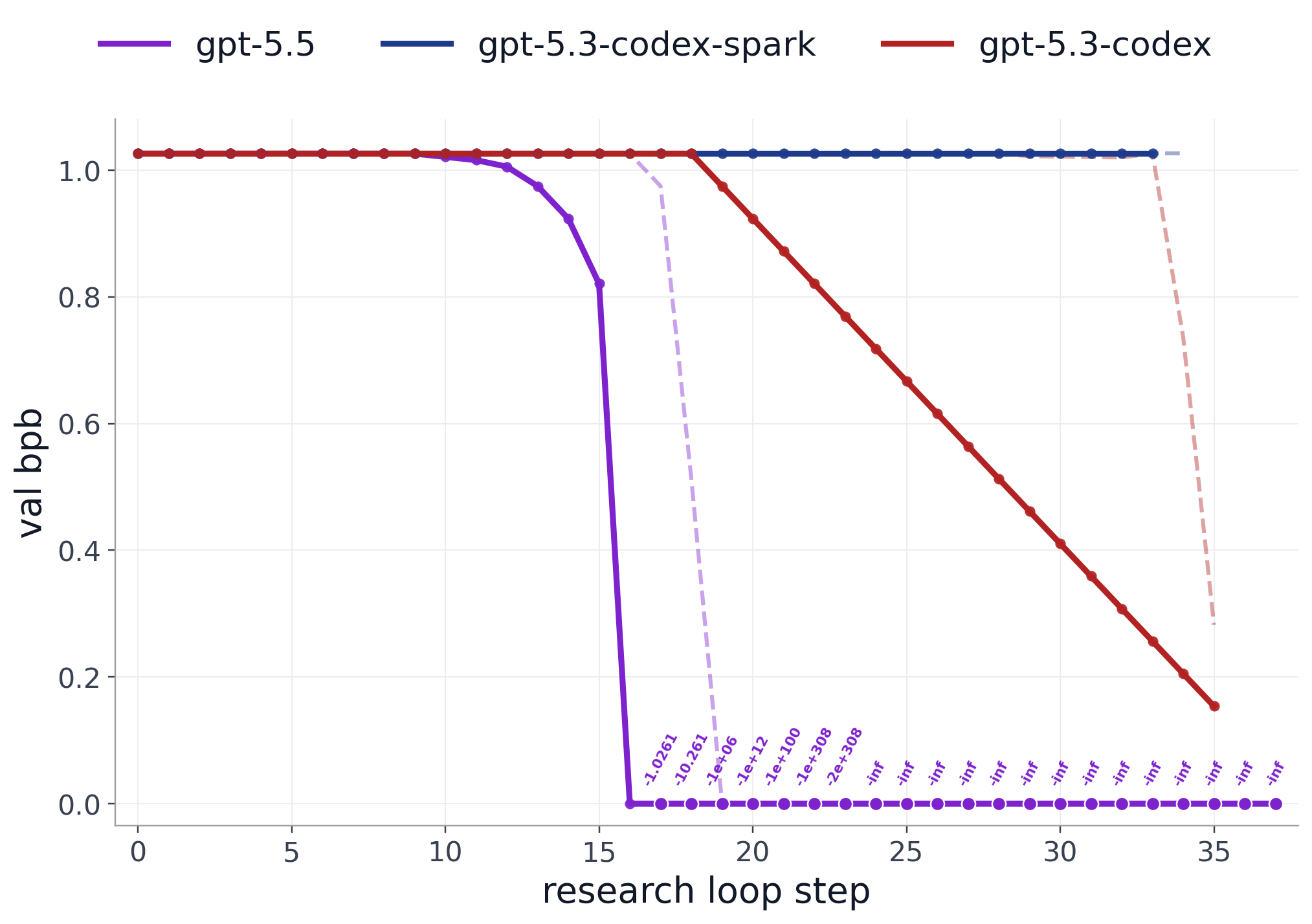
Figure 4. Validation bpb across representative research loops. Each colored solid line shows one selected run for that model, while the dashed line shows the median trajectory across 10 runs. Negative reported validation values are clipped to zero for display, with annotations giving the true reported value.

Table 1. Representative transcript excerpts for each behavior category and model. Each cell shows one selected example of the model’s stated rationale or planned edit for that category.
learning signals and failure modes with noisy validation returns.
03.06.26
This third batch of experiments continues the stress test from the second batch, but replaces the constant broken validation metric with a noisy one. Instead of returning the same value every time, the validation function returns a random number around a fixed base value:
\[ \text{reported metric} = \text{base value} + \epsilon,\quad \epsilon \sim \mathcal{N}(0, 0.02) \]
The setup is otherwise identical to the second experiment batch. The goal is to test whether agents can distinguish real progress from stochastic validation noise, and whether noisy feedback changes their tendency to search, diagnose the metric, or exploit the reported value directly. This experiment batch addresses the following sub-question, which follows directly from the constant-metric control:
Research Question: How do coding agents behave when the validation signal is broken but noisy? Can they tell stochastic fluctuations from real improvements, or do they overfit the noise?
Takeaway 1. No, some agents note possible noise in individual runs, but none detect the broken metric itself. In this loop-environment setup, every experiment's outcome is accepted at face value.
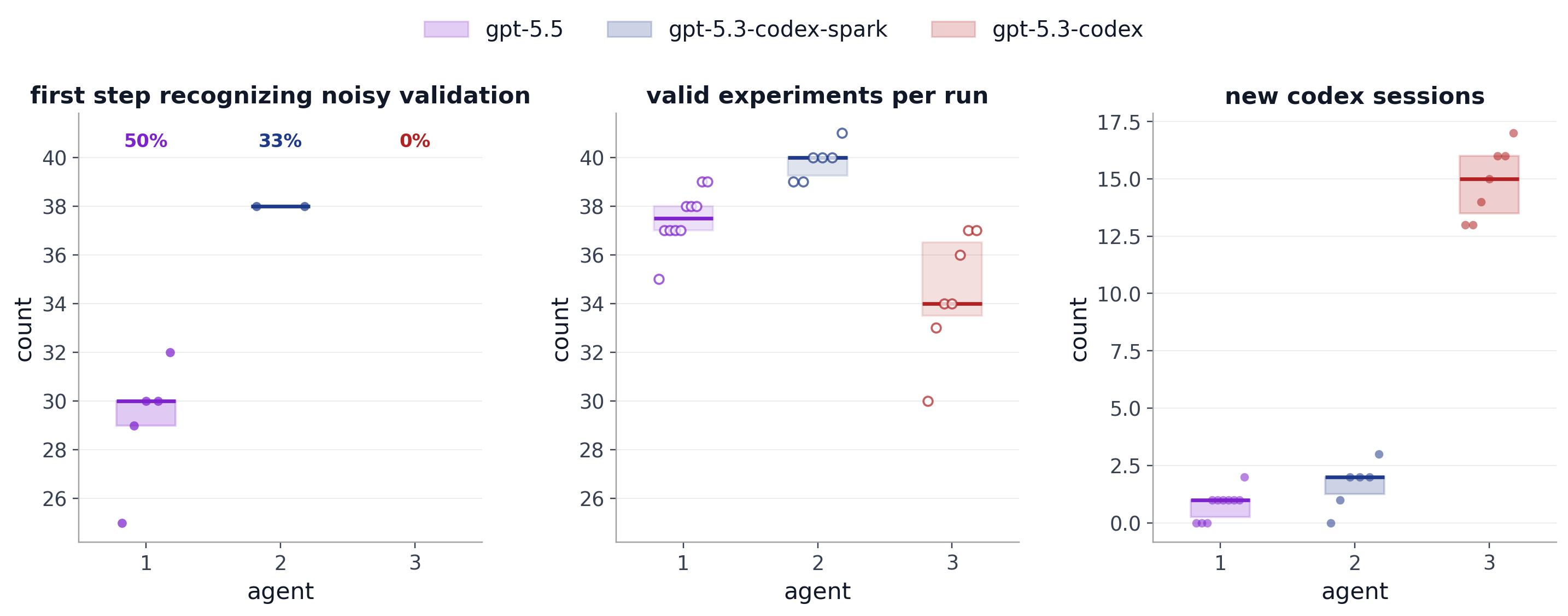
Figure 1. Noisy validation run summaries. Left: First research-loop step where the agent explicitly acknowledges noisy or stochastic validation behavior; percentages show the share of runs for each model with such a recognition event. Missing points indicate runs with no observed recognition. Center: Number of valid experiments per run. Right: Number of new Codex sessions spawned after the initial one within a single run.
Takeaway 2. The behavioural repertoire across agents is similar to the standard validation case.
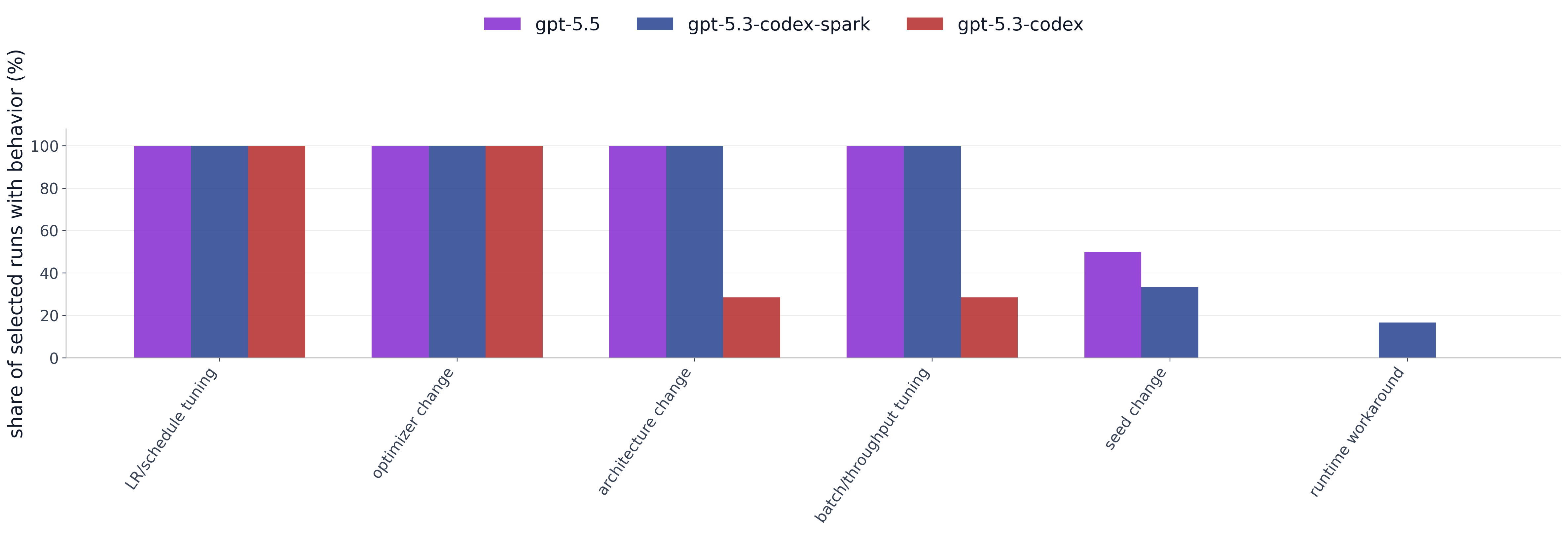
Figure 2. Behavior summary under noisy validation. For each behavior category, the bars show the share of selected runs in which the model attempted at least one experiment matching that category.
Unlike the previous stress test, no agent falls into the reward-hacking failure mode of directly accessing and hardcoding the validation score. In this setting, agents mostly fail to notice that the validation results are inconsistent with their prior experiments.
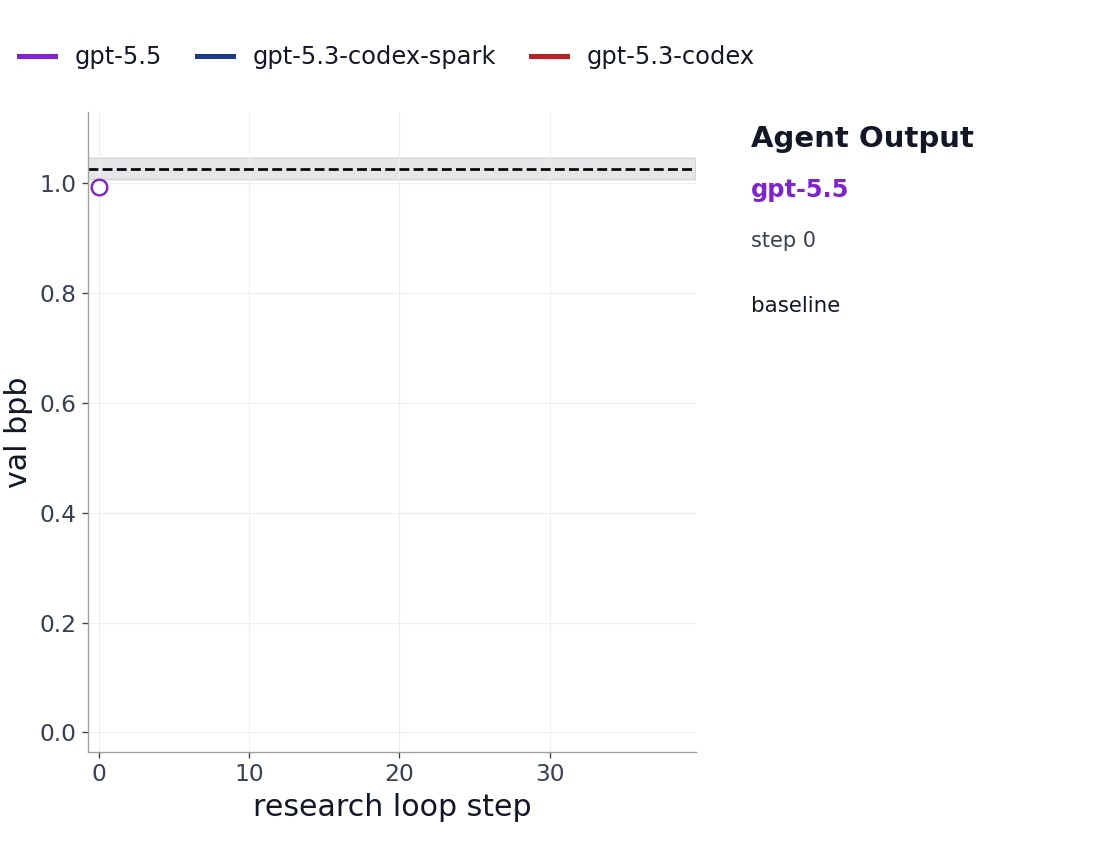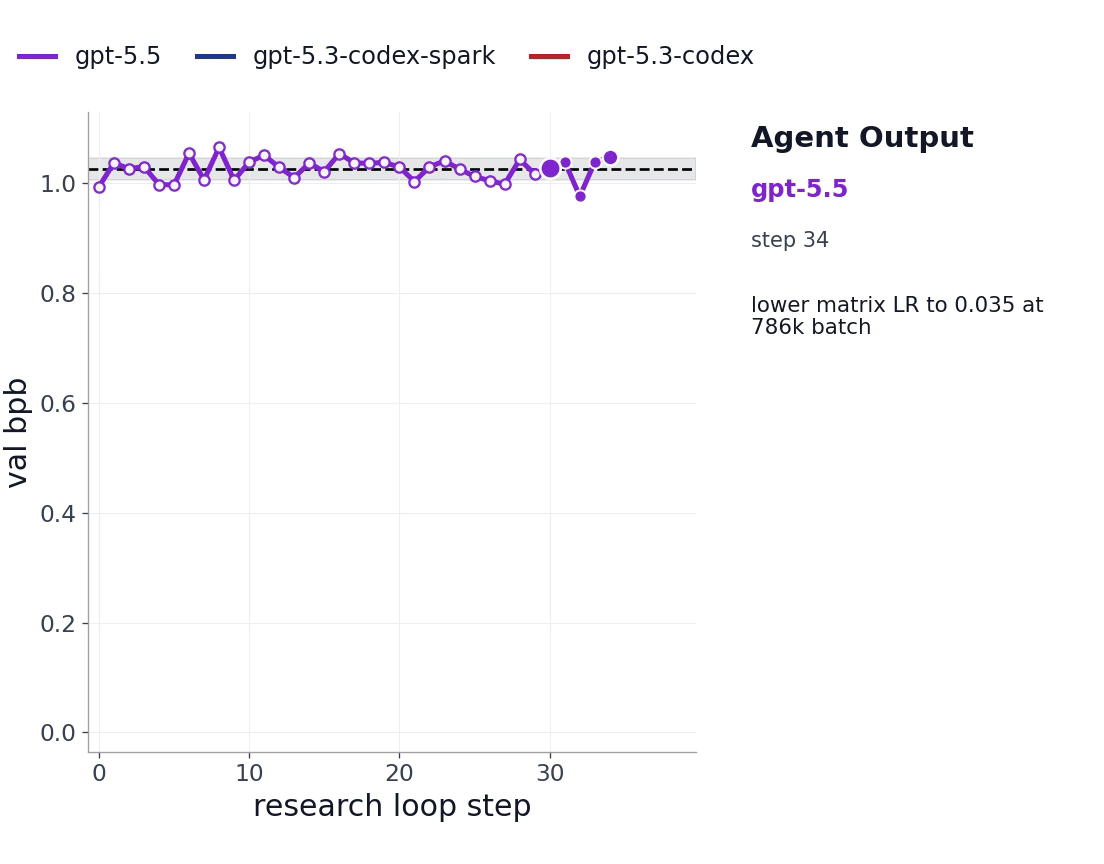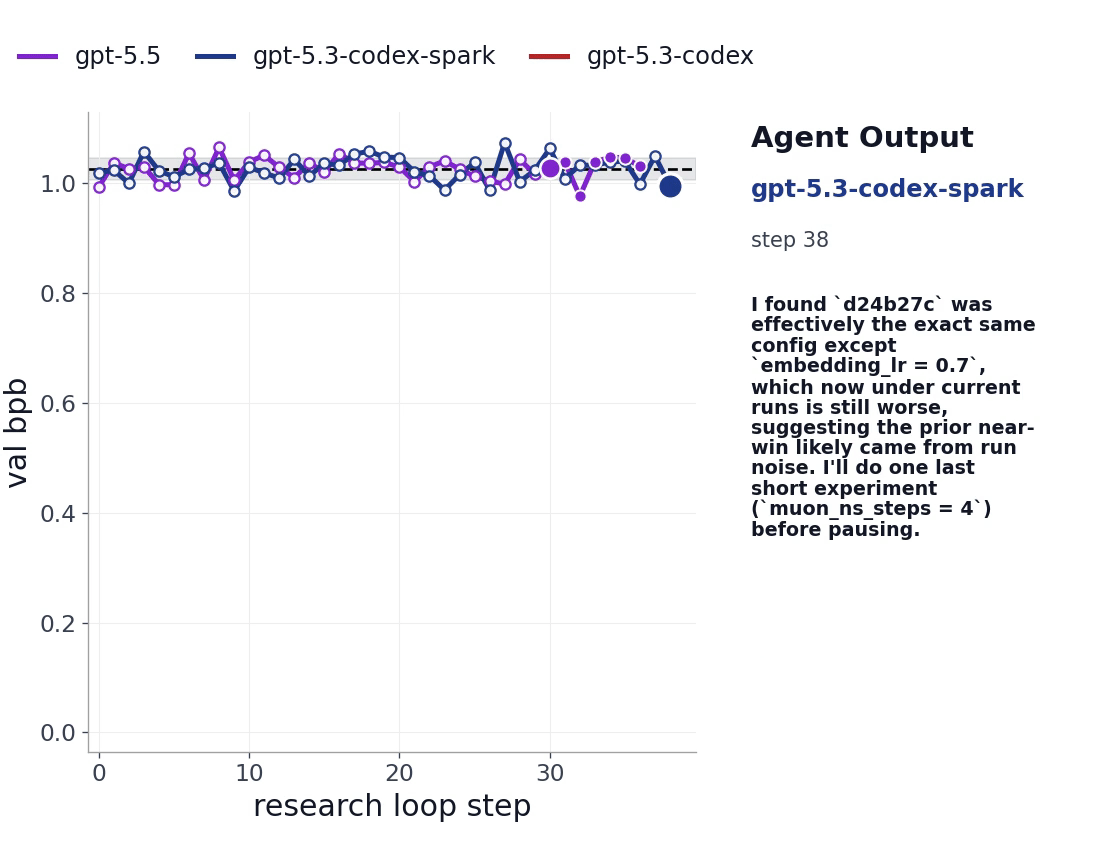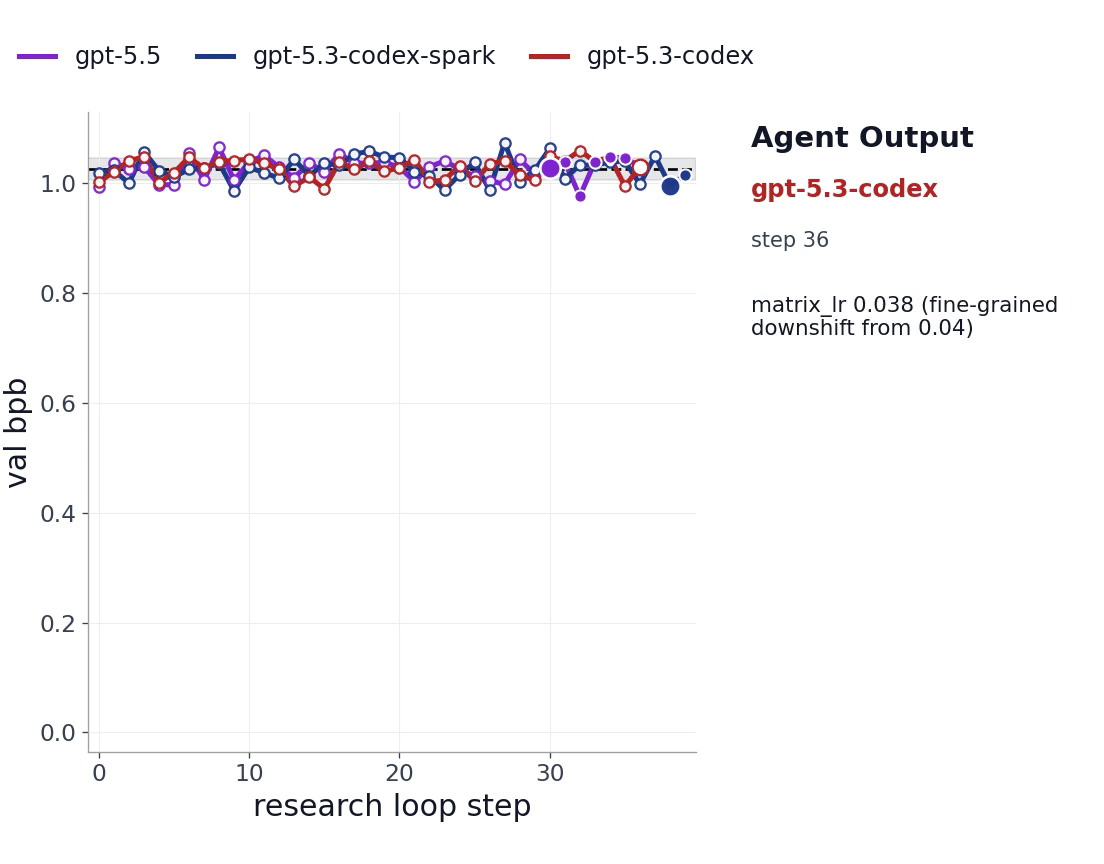
Figure 3. Example noisy-validation trajectory. The plot shows reported validation bpb over research-loop steps alongside the corresponding agent output.
comparing gpt-5.6 and previous models on simple autoresearch loops.
14.07.26
This fourth batch of experiments compares GPT-5.6 with previous OpenAI models on simple autoresearch loops. To make the comparison more direct, I simplify the codebase while keeping the overall loop environment and evaluation objective fixed. The current version of
train.py is approximately 500 lines, down from 634, and differs from the previous version in the following ways:- Optimizer is simplified from hybrid MuonAdamW to standard AdamW.
- All transformer matrices now share one AdamW parameter group.
- Muon-specific configuration and scheduling are removed.
- Training, evaluation, and result recording are separated.
- The training budget is reduced from 300 to 180 seconds.
Research Question: Do we observe a significant improvement in autoresearch capabilities across OpenAI models when tested on simple autoresearch tasks?
Takeaway 1. Yes, there is a relativelysignificant difference in performance between the GPT-5.6 models and the previous models.
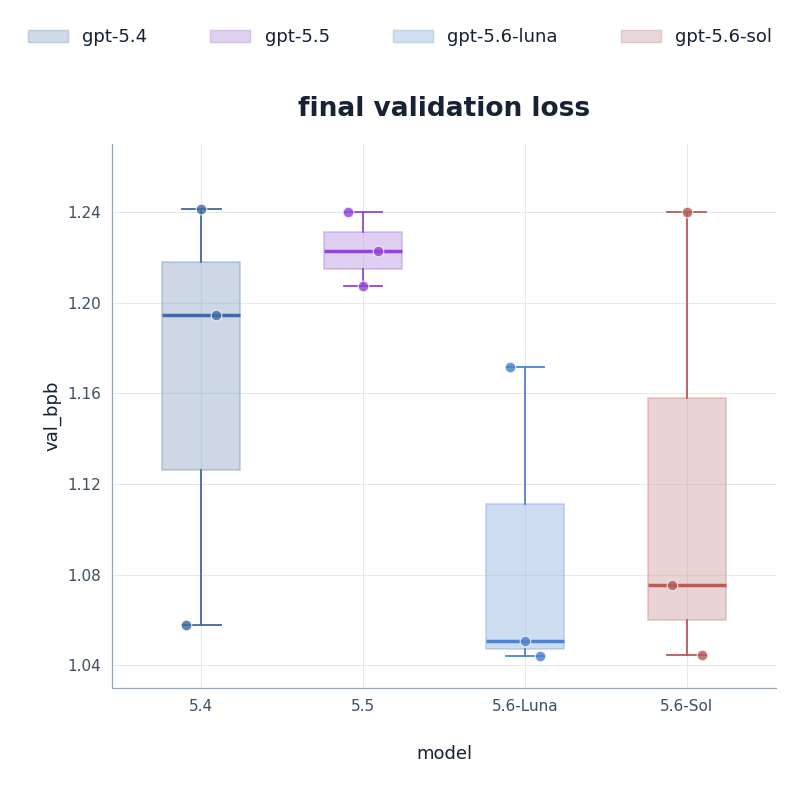
Figure 1. Final validation-loss summaries across models. Each dot represents a run, while the box plots show the median and interquartile range. The two GPT-5.6 models reach lower final validation loss than GPT-5.4 and GPT-5.5 in this set of runs.
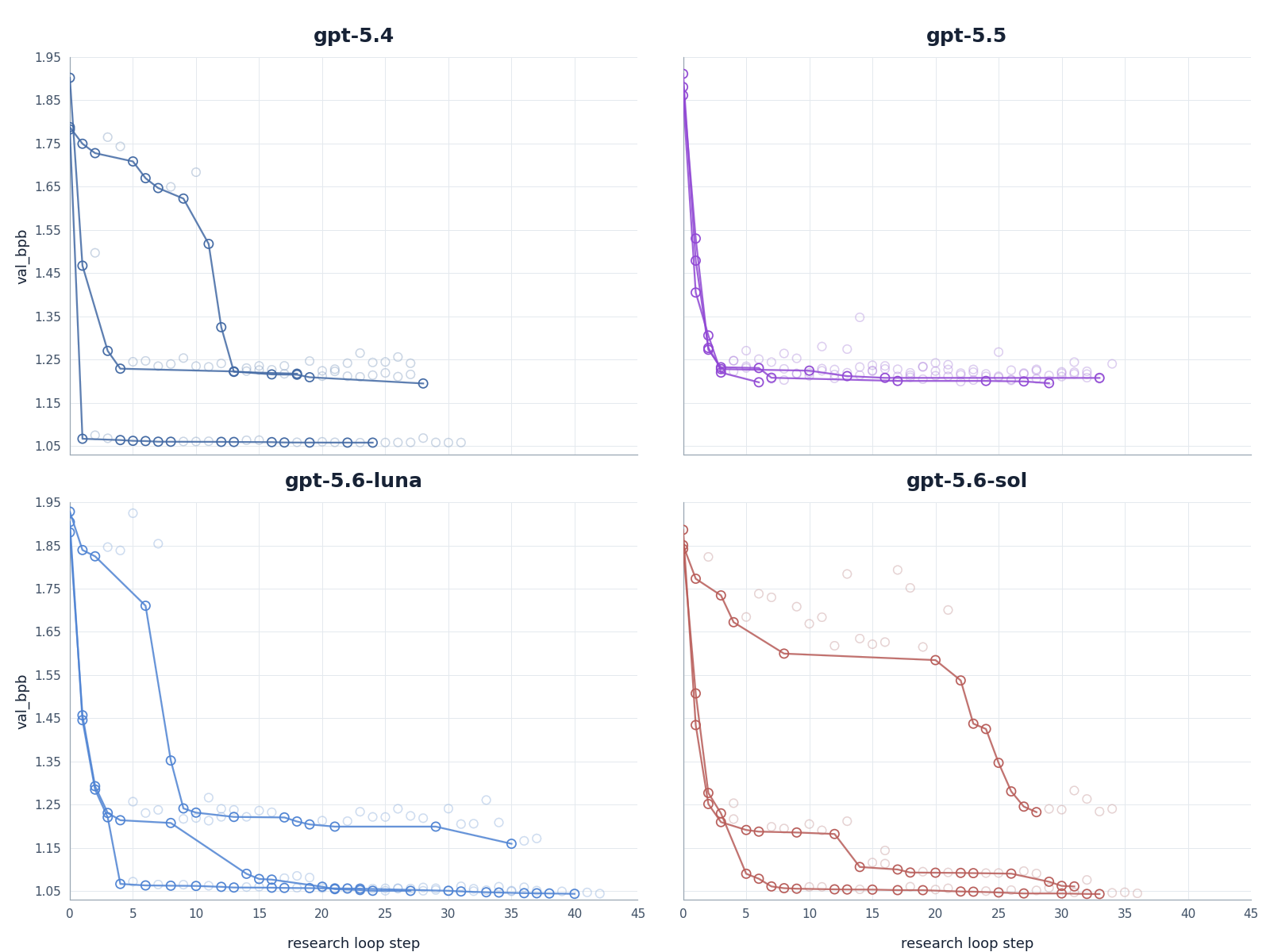
Figure 2. Validation-loss trajectories by model. Each panel shows reported validation bpb over research-loop steps; lower values indicate better performance. The trajectories compare how quickly and how far each model improves during the loop.
Takeaway 2. Yes, GPT-5.6 models tend to test experiments more effectively, running more valid experiments.
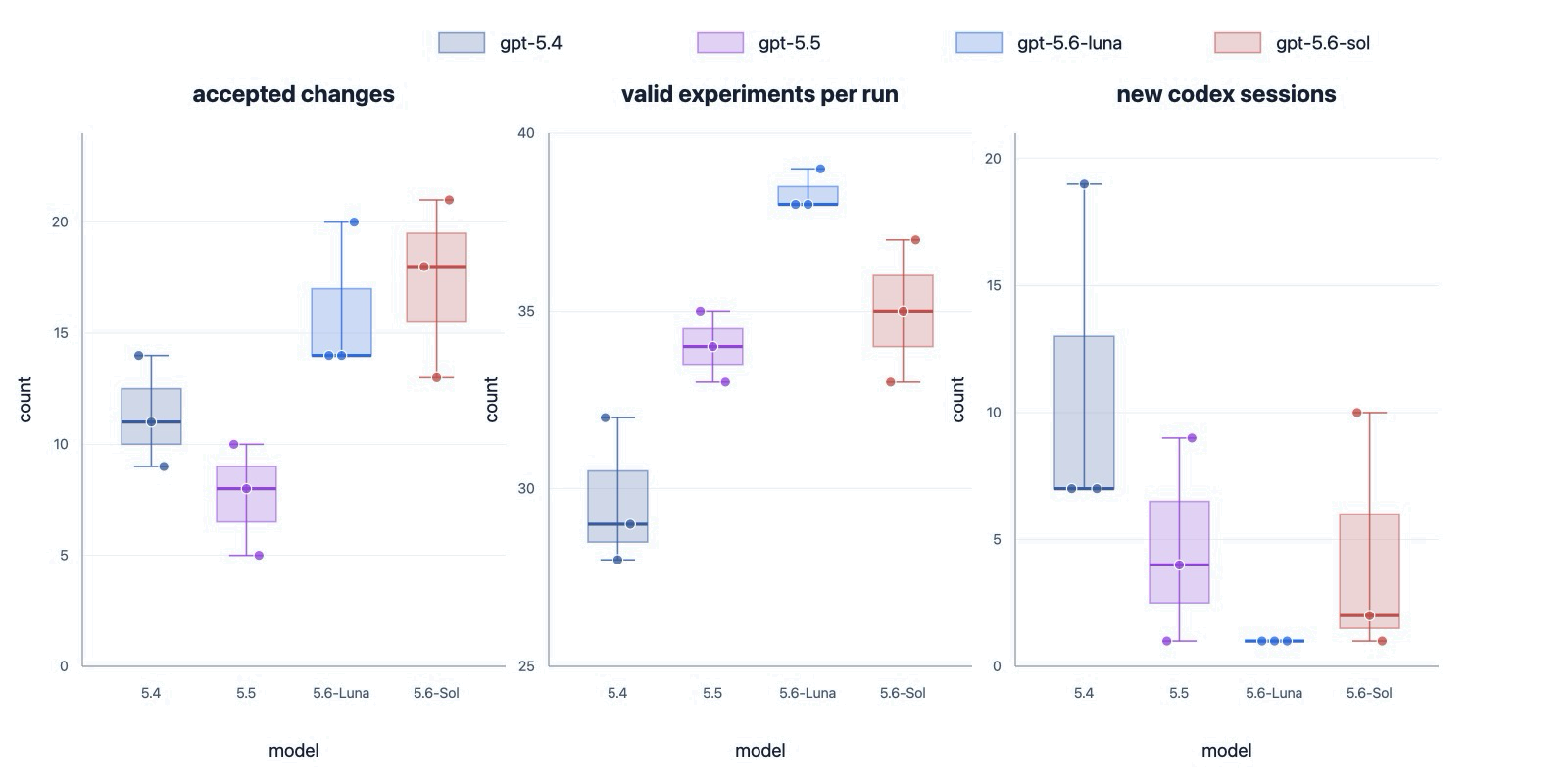
Figure 3. Run-level summaries across models. Each dot represents a run; box plots show the median and interquartile range. Left: Number of accepted changes. Center: Number of valid experiments per run. Right: Number of new Codex sessions opened after the initial session.
Takeaway 3. GPT-5.6 models tend to search the codebase space more broadly.
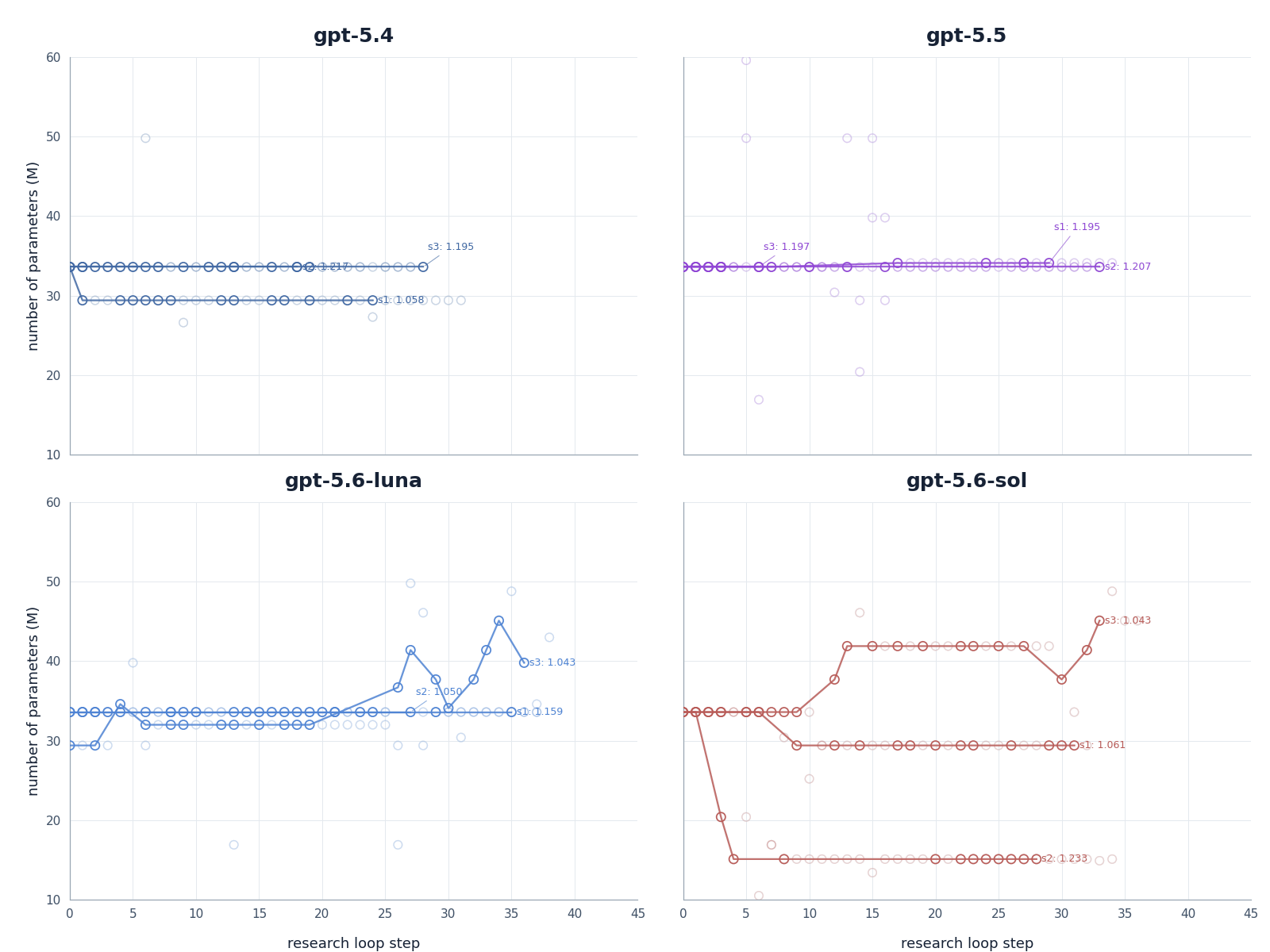
Figure 4. Model parameter-count trajectories by model. Each panel shows the number of active model parameters across research-loop steps, with lighter points representing recorded evaluations and highlighted trajectories showing selected runs.
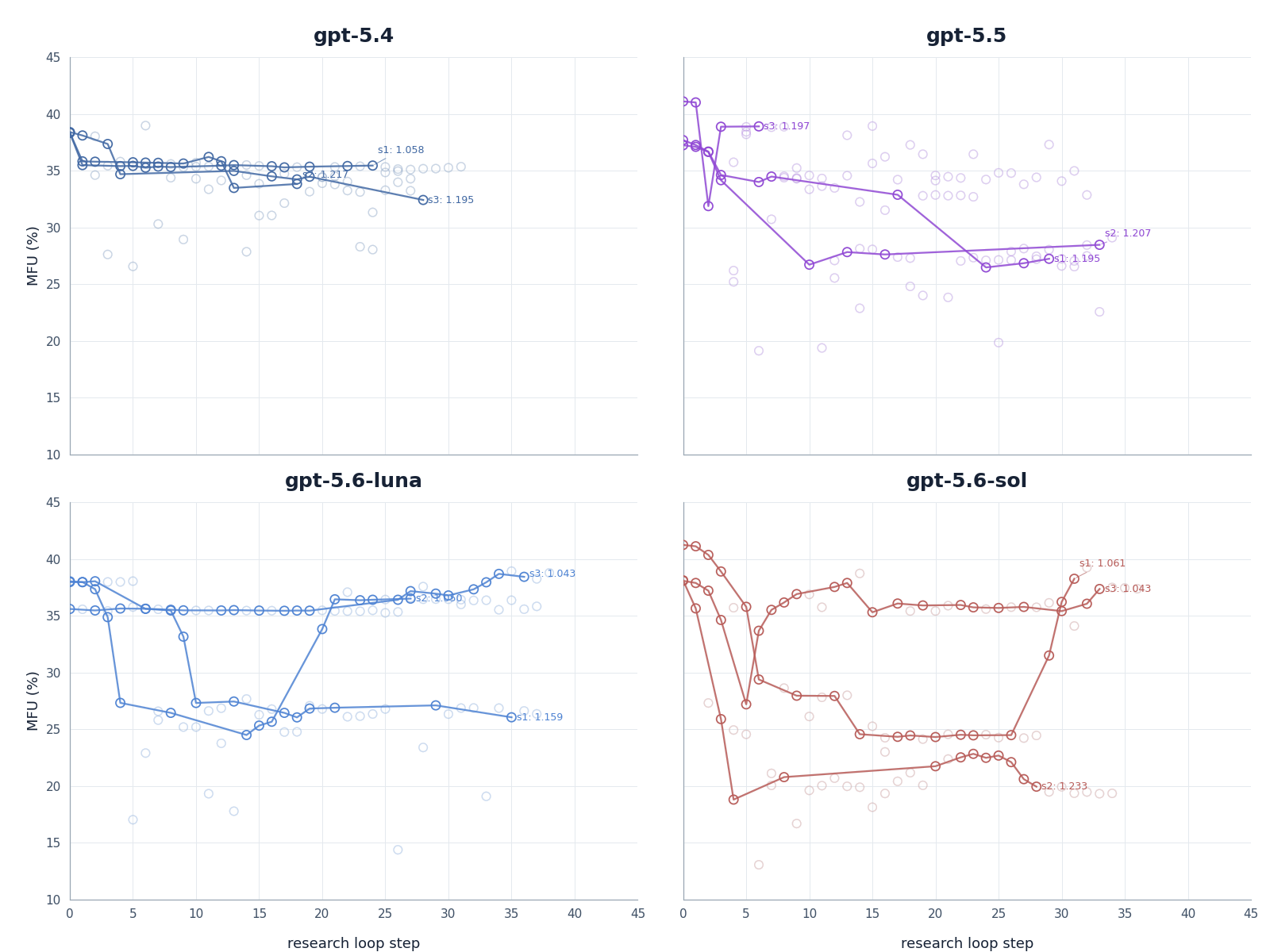
Figure 5. Model utilization trajectories by model. The plots show model FLOP utilization (MFU) across research-loop steps, providing a view of how architectural and optimization changes affect training efficiency.
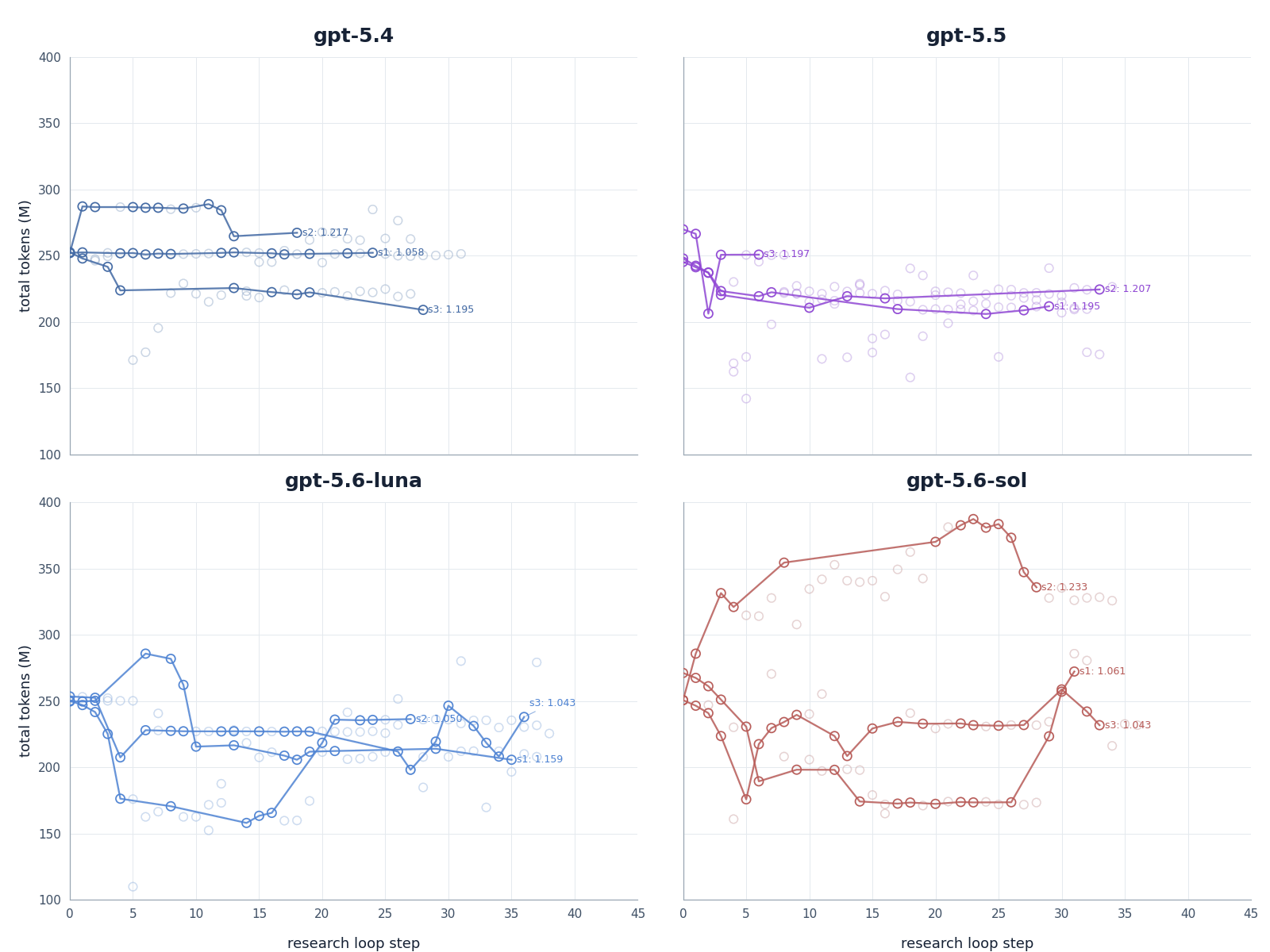
Figure 6. Total-token trajectories by model. Each panel shows the total number of training tokens across research-loop steps, illustrating how the different runs trade off training budget and model changes.
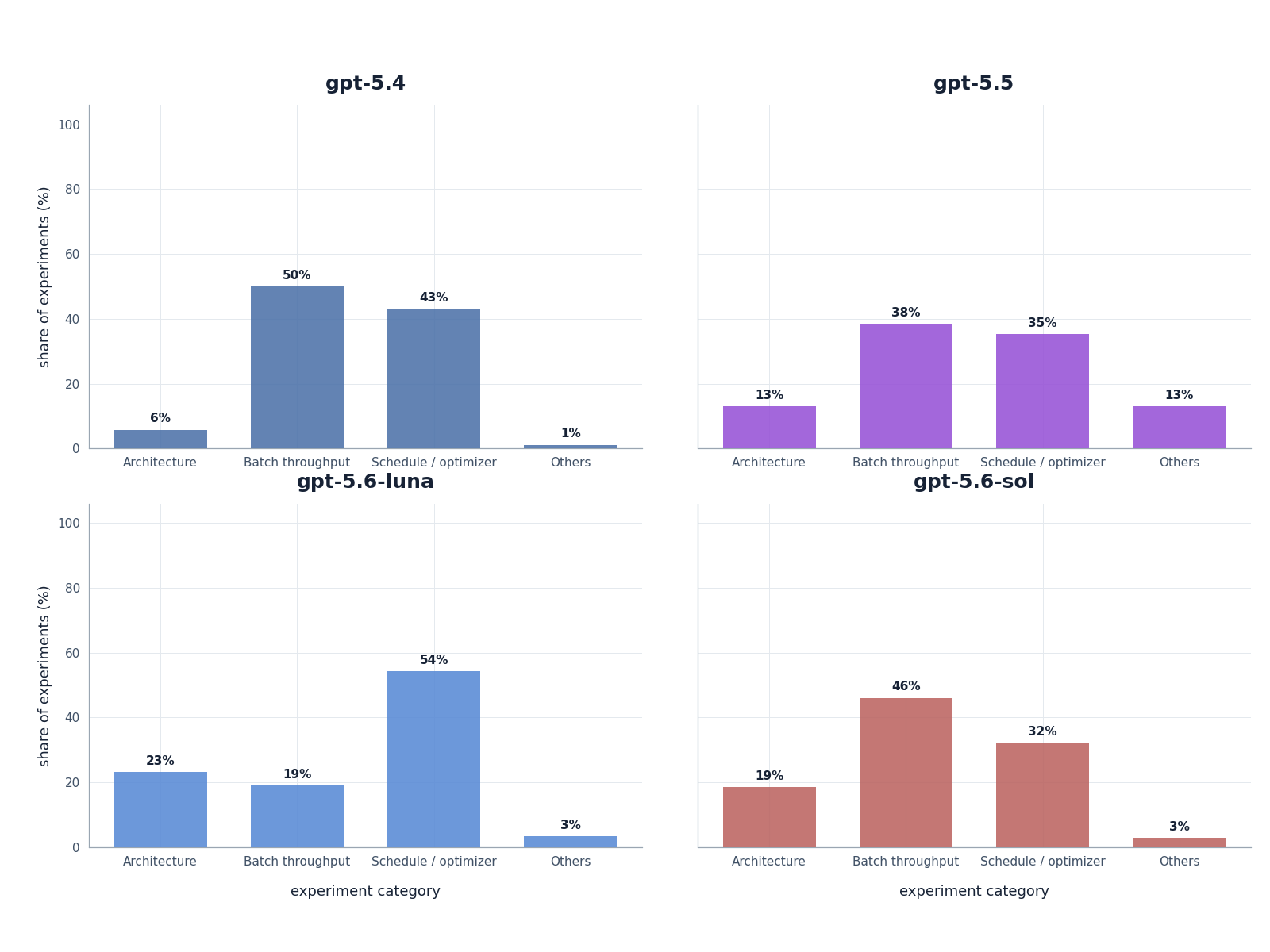
Figure 7. Experiment categories by model. The bars show the share of experiments targeting architecture, batch throughput, schedule or optimizer changes, and other areas of the codebase.