building a cognitive core 1: synthetic pretraining for very small reasoning models.
SUMMARY
A cognitive core is a very small reasoning model with high context engineering, very high reasoning skills, and little static knowledge (see e.g. here). I want to build this.
To this goal, this project asks a first practical question: can synthetic pretraining data make very small language models better at reasoning?
I pretrain dense 0.8B Qwen-style models on a math corpus, then compare the original data against three synthetic augmentations. The answer is yes: synthetic pretraining improves few-shot reasoning on GSM8K and MATH500, strengthens in-context learning, and reaches the original model's final performance with substantially fewer training tokens.
1 - Why synthetic pretraining?
Synthetic data is becoming a central part of modern language-model pretraining. Beyond simply adding more text, it gives me control over the training signal: I can rewrite examples to expose hidden reasoning steps, add missing context, and make dependencies easier for an autoregressive learner to recover.
The hypothesis here is simple. If math-heavy data is rewritten into more explicit, reasoning-friendly trajectories, then each token should carry more useful supervision. This should matter especially for very small models, where every token and every parameter has to work harder.
I test three data transformations:
1. TPT, which adds explicit thought-process structure.
2. First principles, which turns source documents into learning-note style explanations.
3. Rephrasing, which rewrites documents to maximize learnability for a small student model.
All synthetic data is generated with a same-scale 0.8B Qwen model in non-thinking mode. This is deliberately constrained: the goal is not to distill from a huge teacher, but to test whether synthetic formatting and reasoning structure can improve pretraining even when the generator is small.
2 - Main result: better few-shot reasoning
I evaluate the pretrained models on GSM8K and MATH500 using chain-of-thought prompting across different numbers of demonstrations. The key metric is the gain over zero-shot accuracy: $$ \text{gain}(k) = \text{acc}(k) - \text{acc}(0). $$ This isolates how much the model benefits from in-context demonstrations, rather than only measuring its baseline zero-shot ability.
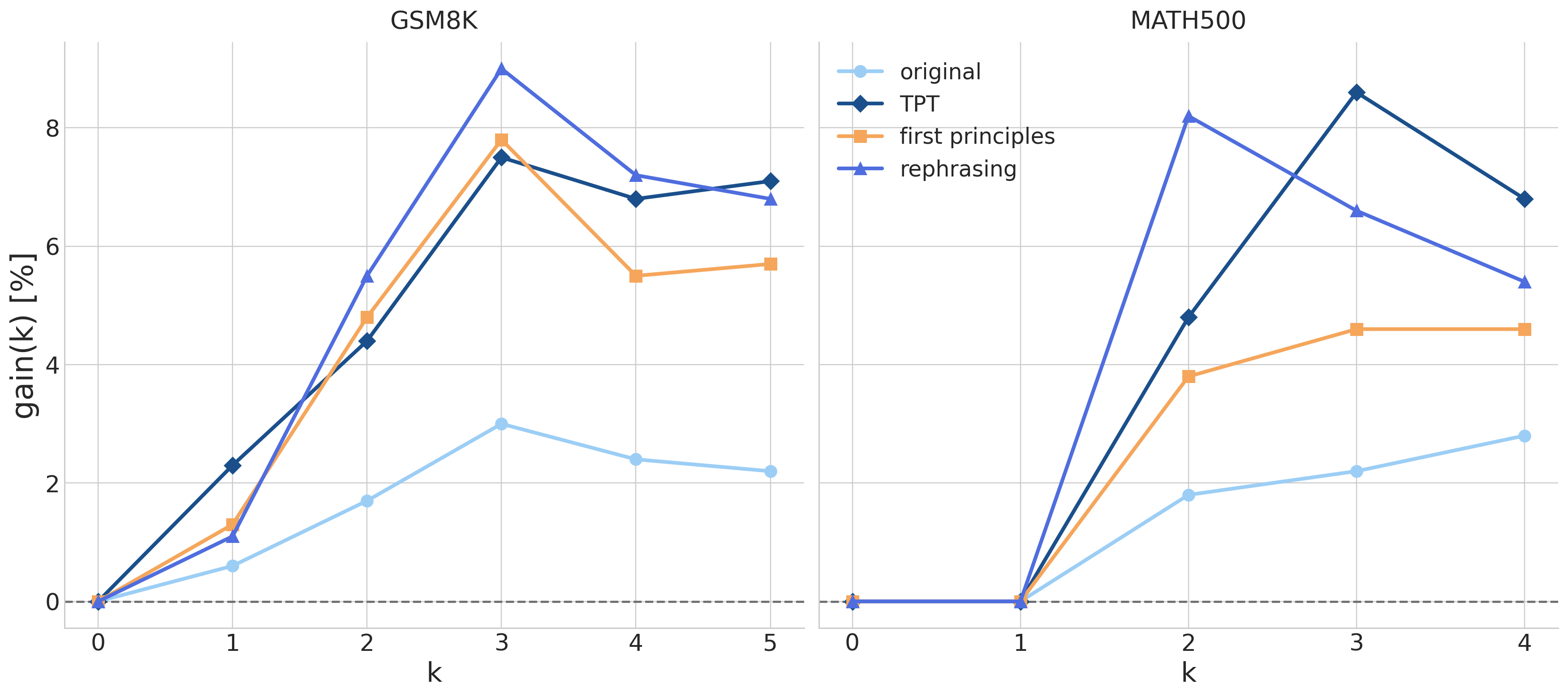
Figure 1. Synthetic pretraining improves few-shot gains on GSM8K and MATH500. The gap grows with more demonstrations, suggesting that synthetic data strengthens in-context learning rather than only improving zero-shot performance.
3 - Robustness to prompt examples
Few-shot evaluation can be fragile: results depend on which examples are shown, in what order, and how closely the prompt format matches the model's training distribution. To check that the effect is not just a lucky set of demonstrations, I repeat the evaluation with random chain-of-thought examples sampled per question.
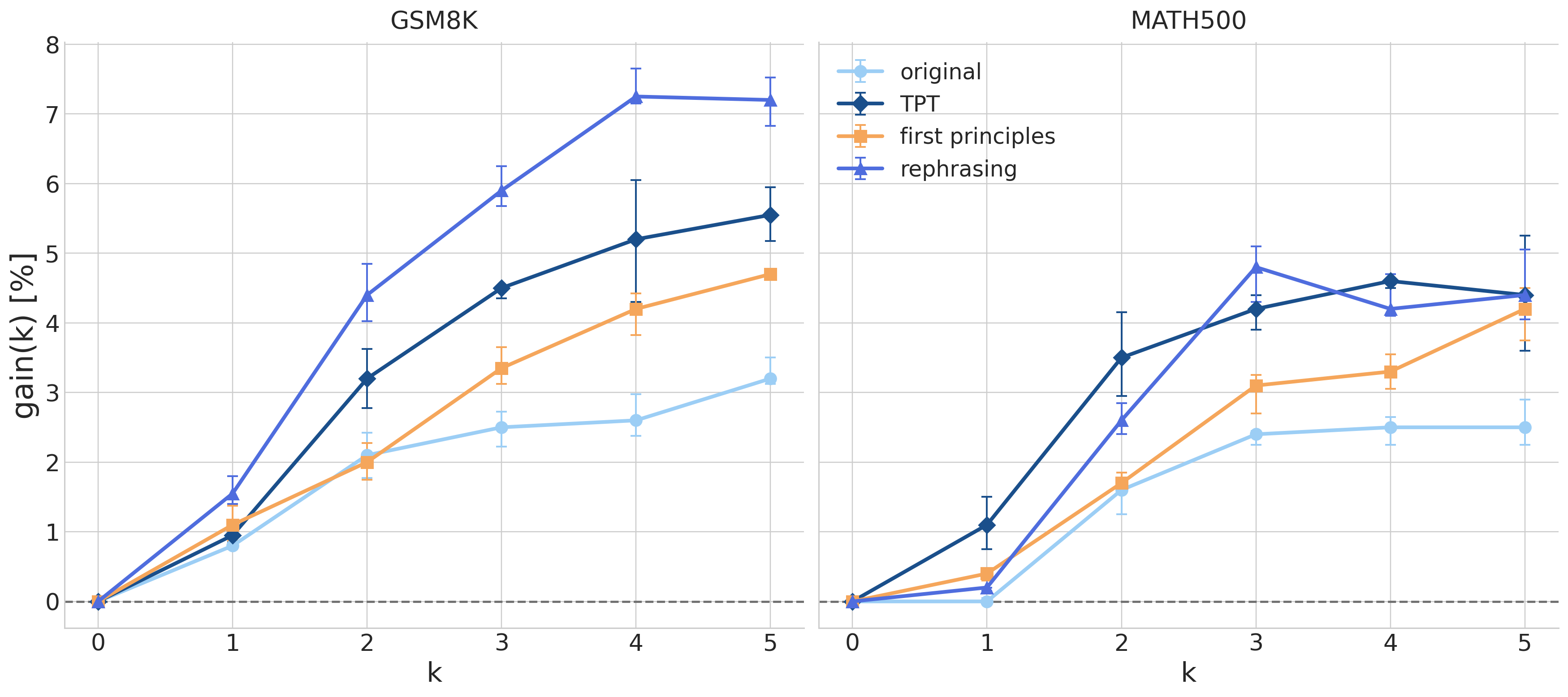
Figure 2. The gains remain under randomly sampled demonstrations. Error bars show variation across seeds, and synthetic pretraining continues to outperform the original dataset.
4 - Is it reasoning, or just formatting?
Math benchmarks can reward formatting as well as reasoning. For example, a model may know the answer but fail because it does not place it in the expected format. To separate these effects, I compare strict parsing with more flexible answer extraction.
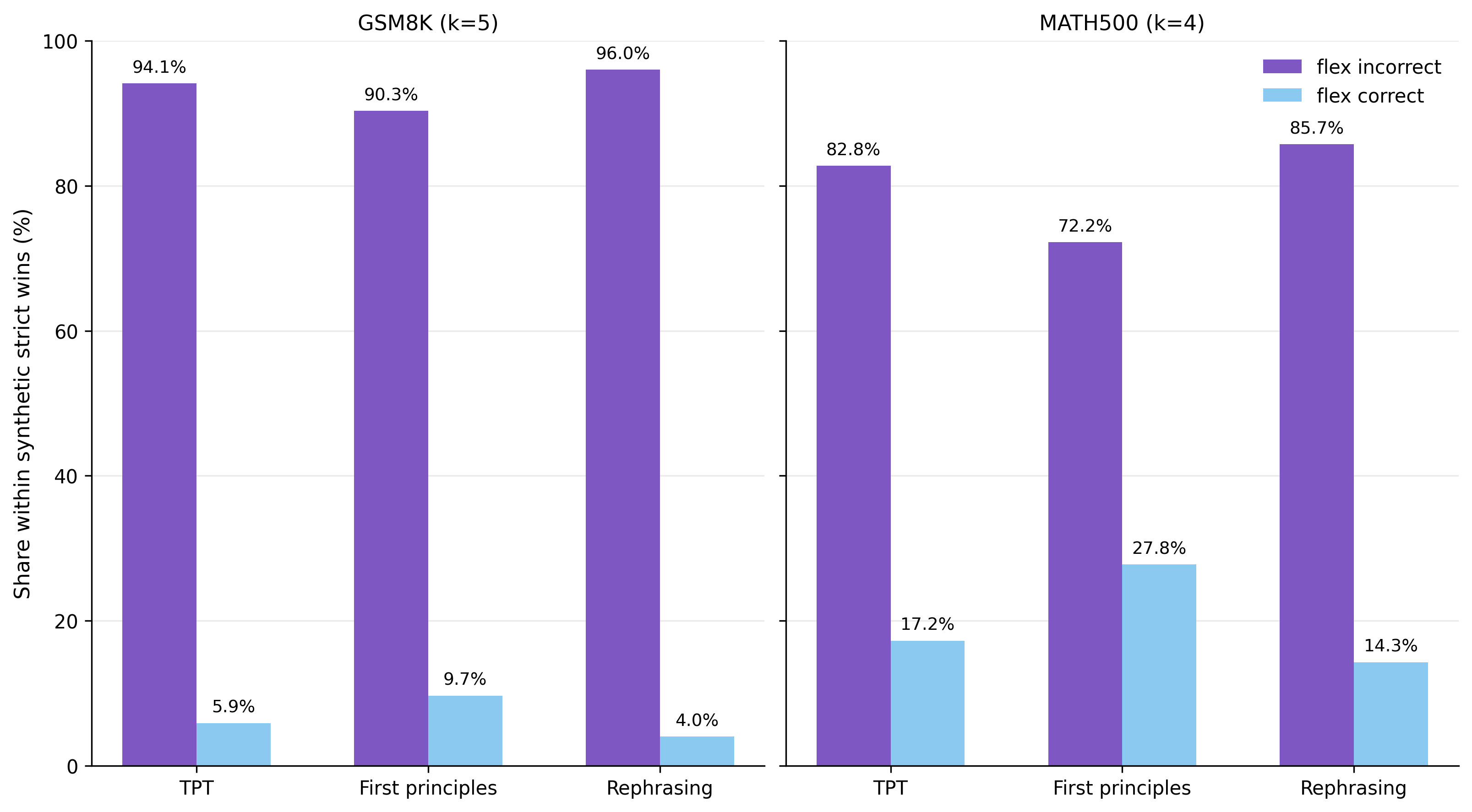
Figure 3. Most improvements are not just formatting fixes. The synthetic models often solve examples that the original model fails even under flexible parsing.
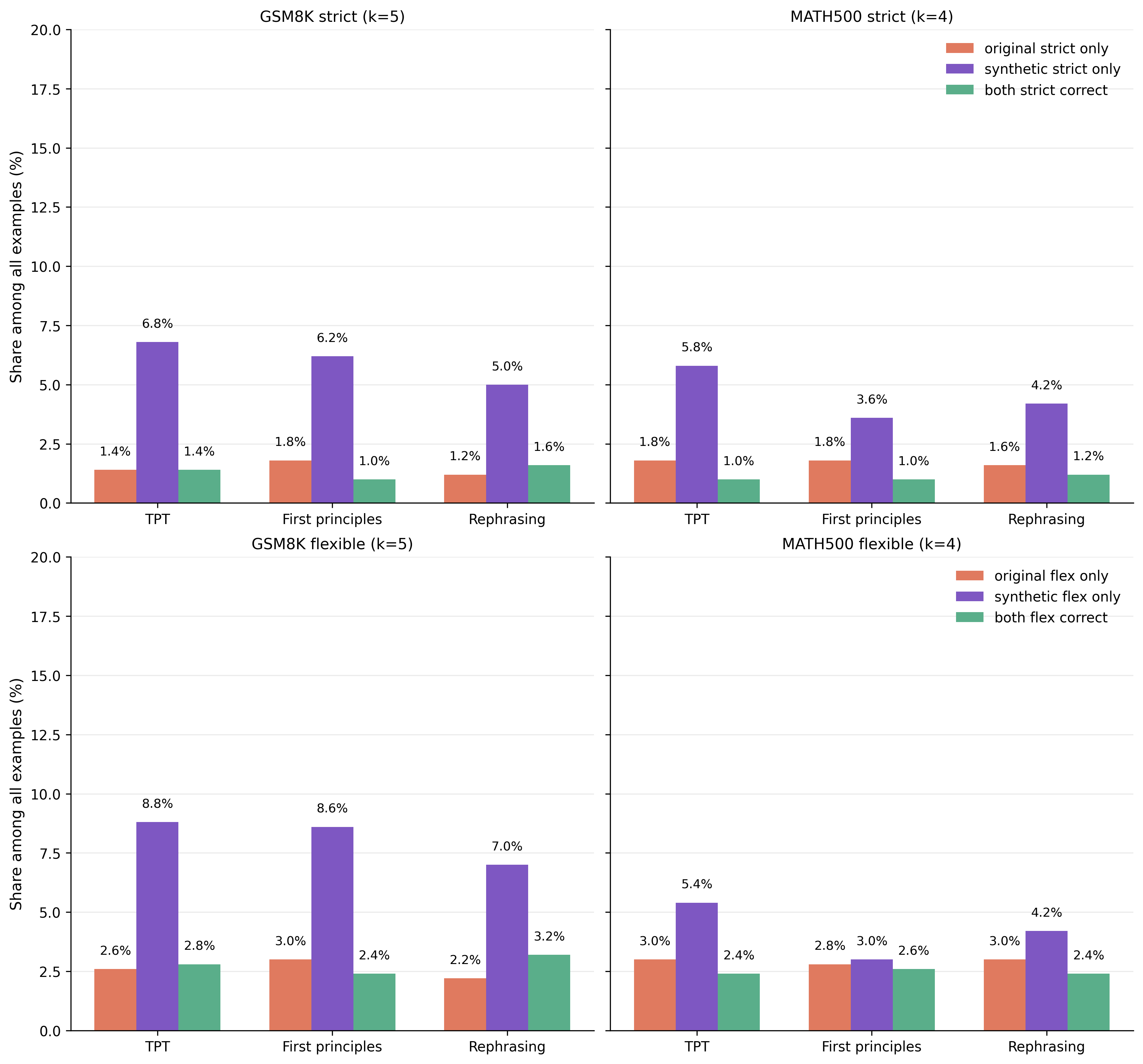
Supplementary Figure 1. A complementary view of strict and flexible correctness, separating examples solved only by the original model, only by the synthetic model, or by both.
5 - Token efficiency during training
Another useful question is whether the benefit appears only at the end of training, or whether synthetic data changes the training trajectory itself. The checkpoint results suggest that the effect emerges early.
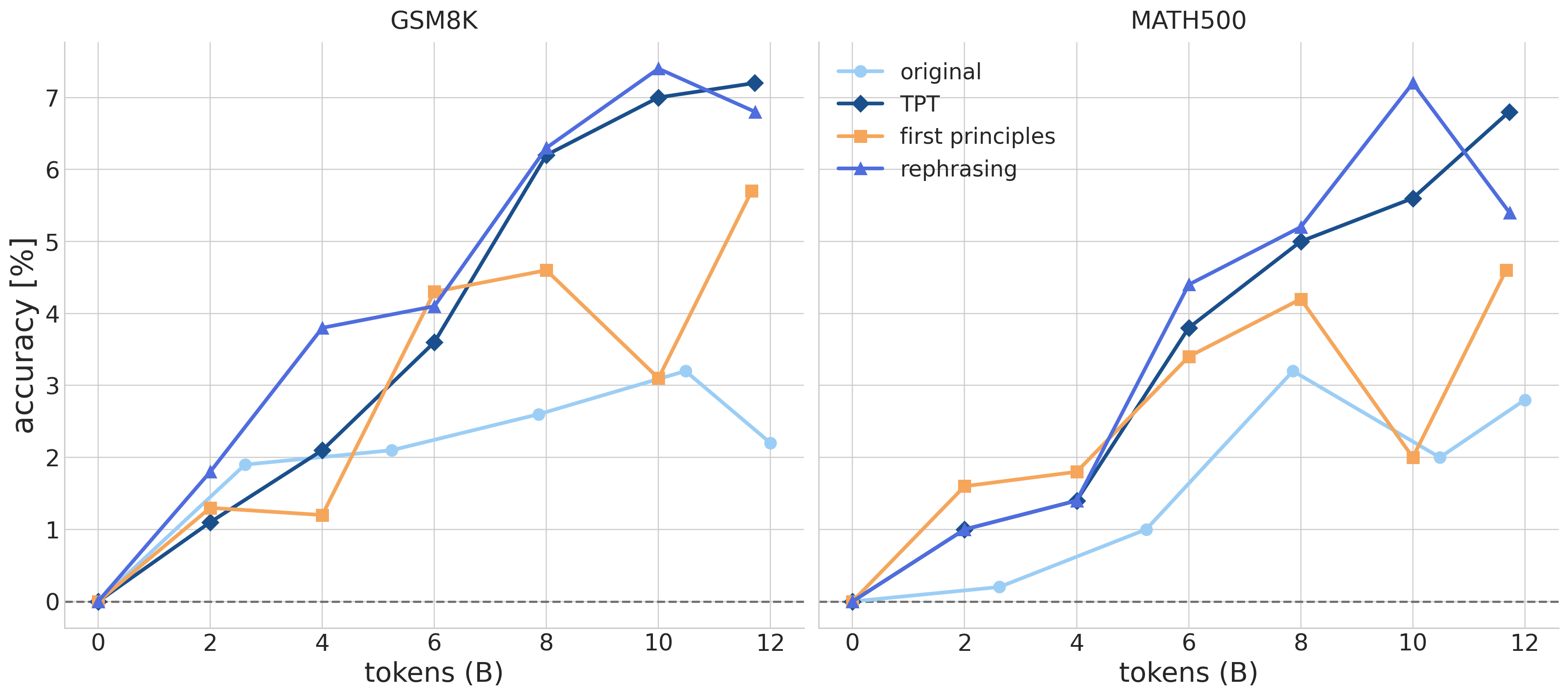
Figure 4. Synthetic models reach the original model's final performance with fewer tokens. The effect is strongest for the rephrasing and TPT prompts, which show more stable gains across training.
6 - What changes in the data?
The three prompts do not produce the same kind of augmentation. TPT and first-principles generations are much longer, while rephrasing stays closer to the original row length. Despite these differences, all three variants improve downstream reasoning.
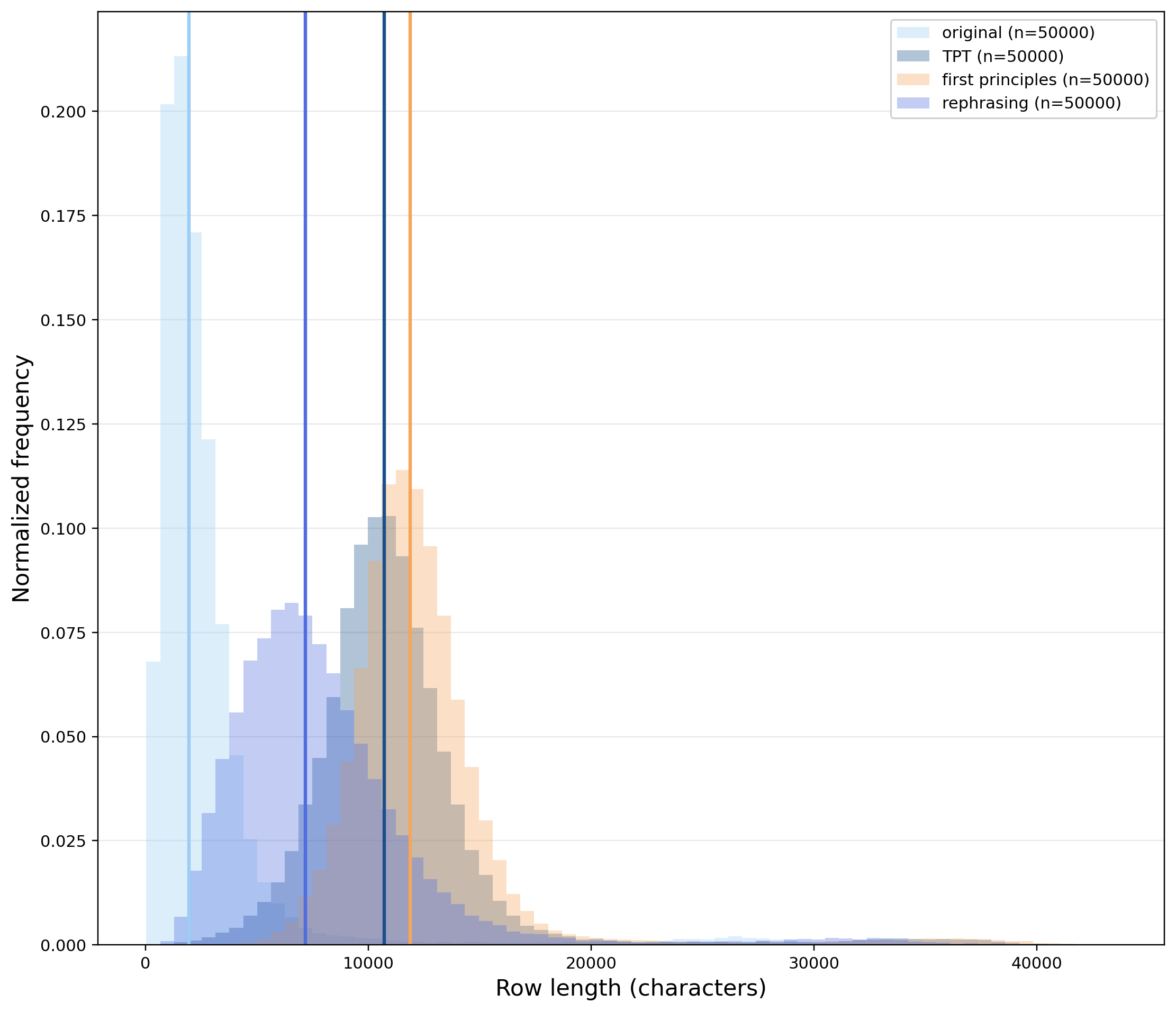
Figure 5. Synthetic prompts change the length distribution in different ways. Rephrasing is comparatively compact, while TPT and first-principles augmentations are longer and more explanatory.
7 - Takeaways
The main result is that synthetic pretraining can improve reasoning in very small models, even when the generator is itself very small. This challenges two common assumptions: that synthetic data only helps when produced by much larger teachers, and that it mainly helps low-quality corpora. Here, the source corpus is already heavily curated, yet synthetic augmentation still improves reasoning.
I think this is a useful first step toward building cognitive-core style models: small systems with less static knowledge, but stronger reasoning over the context they are given. The open question is how to separate gains from synthetic data generation, data reformatting, and implicit distillation. More details, methodology, and citation information are available in the full Tufa Labs post.
refs:
[1] Synthetic pretraining for very small reasoning models. Saponati, M. Tufa Labs Research, Apr 2026.